

Det. Eng. Weekly #120 - Gems from the 2025 Trenches, Part 2
are u a gem cuz i want u 2 be mine
Welcome to Issue #120 of Detection Engineering Weekly!
This is Part 2 of 2 series on Detection Engineering Gems I’ve posted since the beginning of the year.
💎 Detection Engineering Gems 💎
March 12 Issue
Diving Into AD CS: Exploring Some Common Error Messages by Jacques Coertze
This is an excellent, up-to-date post on how Active Directory Certificate Services (AD CS) works and doesn’t work from a red teamer perspective. Readers of this newsletter know that I am by no means a Windows expert, but I am learning a lot more reading detection engineering posts that study the Microsoft ecosystem. If you want a crash course on AD CS, this is a must-read post.
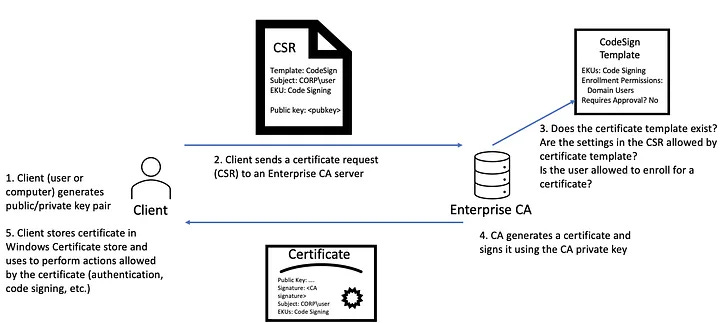
Whenever you land inside an Active Directory (AD) environment, you want to find ways to laterally move to the crown jewels: administrator accounts and AD servers. One way to do this is to abuse how the AD CS deployment is configured. There’s all sorts of snazzy tooling to help you find password hashes via Kerberoasting, but you can also use some of the techniques Coertze outlines in this research.
The cool part about examining how a red teamer succeeds or fails is the detection opportunities you find along the way. Coertze investigates 3 common error messages when trying to abuse AD CS and gives a ton of insight into how these network communications between a client, a key distribution center, and an AD server work.
The weird scenario Coertze found was when you issue an authentication request for a valid user account you control locally, you expect an NTLM password hash in response. But you can use that same certificate template, modify an attribute from client to server authentication, and request authentication for the remote DC accounts. Basically, certificate template enforcement is not a feature in some scenarios. According to Microsoft, this works as expected, and administrators must manually revoke these certificates. Classic.
March 19 Issue
Measuring the Success of Your Adversary Simulations by Jason Lang
This blog outlines a fantastic, modern, and applicable approach to Adversary Simulation. Lang describes the differences between a pure pentest and a more collaborative red team engagement, and you can see that detection validation and gap analysis are front-and-center. To me, an adversary simulation exercise is akin to a threat-hunting exercise. You start with a hypothesis, in this case, a technical control you want to test, and then you have the red team work backward to find weaknesses and attack paths that can test that technical control.
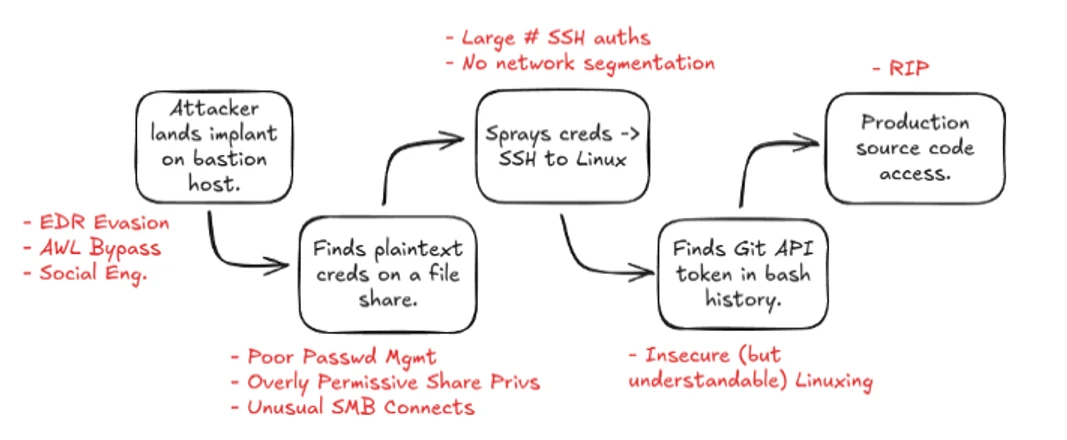
I love the defensive enlightenment section. The red team should never be positioned as “us versus defenders” because it doesn’t drive outcomes other than who was right and who was wrong. Instead, a productive engagement, as Lang puts it, should result in testing the controls and detection and providing expertise to ensure the organization fills in the gaps found in controls and detections.
Honestly, red teamers make some of the best detection engineers.
April 2 Issue
Entropy Triage: A Method to Repair Files Corrupted by Failed Ransomware Encryption by James Gimbi
My friend James has been in the incident response and detection field for over 10 years (about the same as me; it turns out we met in college :D ), and I've always loved reading his work since then.
Ok, so, basically, ransomware operators suck. They suck for many reasons, and we can all rant on the ethical nature of their operations. They also can suck at the technical parts of ransomware since they are not crypto experts. So, sometimes when they run an encryptor on a victim environment, they partially encrypt data due to lousy luck, poorly built tooling, or a defender disrupted their operation.
When this happens, and the victim obtains a decryptor, the decryptor can't account for partially encrypted and corrupted files, so the the decrypt operation fails. James put a great visual in the post explaining this:
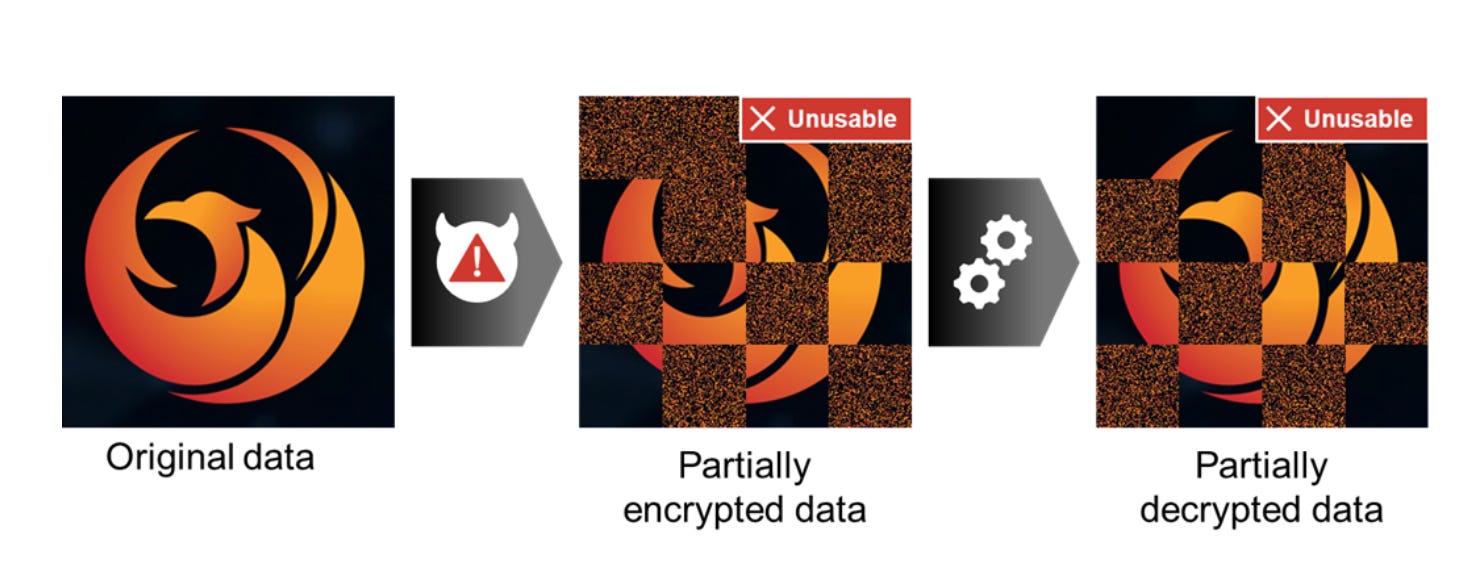
His research focuses on decrypting partially encrypted and corrupted data from ransomware infections and returning them to normal. He does this by combining the threat actor-provided decryption tool, the decryption key, and some clever information theory techniques.
Leveraging Shannon Entropy, James could measure a potentially encrypted block before and after running the decryption routine. If the entropy was lower after decryption, then it was a successful decryption, and that block was written to disk. If the opposite happens, then he assumes the block was already decrypted and doesn't change the block.
His firm boasts (and rightfully so) an over 90% success rate in using this technique on corrupted files.
April 9 Issue
Detecting C2-Jittered Beacons with Frequency Analysis by Diego Valero Marco
Heck yes, a detection blog using mathematics! In Issue 107, I listed a blog by Mehmet Ergene using a bucketing technique with MDE to detect C2 callouts. The assumption behind C2 callbacks is that infected machines check in with the C2 server to help the attacker know that the infection is still active. Using Window techniques helps catch "bins" of time, where you can possibly find spikes in traffic. Diego builds on top of Mehmet's technique by using Fourier analysis.

The basic foundation of Fourier analysis rests in decomposing a Signal, in this example C2 flow log traffic, and finding "spikes" in that Signal that could indicate something unusual. The above picture (stolen from Diego's blog) represents what they are trying to find. Blue indicates network traffic, red indicates the C2 beacon, and green means the combined traffic. Using a Fourier transform over the three datasets helped him find a C2 beacon traffic calling out.
They go into much more detail on using bucketed time Windows, similar to Mehmet's work, on top of many FFT's to detect spikes. It's definitely worth the read!
April 16 Issue
Inside Riot Vanguard’s Dispatch Table Hooks by Archie
Like most anti-cheat-related posts I post here, this one is dense and full of technical information on a Kernel-level anti-cheat system. Archie's blog focuses on Vanguard, Valorant's anti-cheat system. Unlike other posts I've linked with anti-cheat software, Vanguard is a Kernel mode driver, unlike a user mode driver, which means it's akin to a Windows rootkit or EDR. The difference between a Rootkit or an EDR is that it only runs when the Valorant process is started, so it's hyper-focused on catching cheats inside Valorant.
When you see rootkit-like functionality, you should ask yourself: What is it hooking? The idea behind function hooking is pretty simple: You can add, remove, inspect, or edit function parameters and data for analysis or evasion. Archie's research focuses on the Nt!SwapContext hook derived from Kernel device drivers.
Vanguard is loaded via a Kernel driver. It loads a Windows hardware abstraction layer (HAL) structure and sets itself as one of the first entries in that structure, called the HalPrivateDispatchTable . Once the function entry is replaced, it points to a Vanguard-controlled function, specifically hooks Nt!SwapContext calls are called anytime a thread context switches. It's a clever hook since it's frequently called on Windows.
I worked with ChatGPT for a more visual representation here: here:
+-----------------------------+
| Windows Kernel Space |
+-----------------------------+
|
v
+-----------------------------+
| HalPrivateDispatchTable |
| (Function pointers) |
+-----------------------------+
|
v
+-----------------------------+
| nt!SwapContext |
| (Context switch function) |
+-----------------------------+
|
v
+-----------------------------+
| Vanguard Hook |
| (Monitors thread switches) |
+-----------------------------+
[**] Thread switch happens via nt!SwapContext [**]
+-----------------------------+
| System Call Entry Points |
+-----------------------------+
|
v
+-----------------------------+
| KiDynamicTraceMask / |
| PerfGlobalGroupMask |
| (System call tracing) |
+-----------------------------+
|
v
+-----------------------------+
| Vanguard Monitoring |
| (Tracks system calls) |
+-----------------------------+
April 30 Issue
Can We Stop Documenting Our Detections? by Gary J. Katz
The most important things you do day-to-day as a security engineer are often the most tedious. This is mainly because repetitive tasks, such as documentation, aren't meant for a machine, but for another human. If you ship several rules on finding malicious activity in network logs and don't document any investigative playbooks associated with the rules, are they valuable?
Of course not! The investigation is such an essential part of the funnel of fidelity; why stop at alerting? So, if documentation and playbook writing is painful, can anything help with investigations to relieve that pain? Gary asks this question as it applies to LLMs. He performs a super interesting study on how Elastic's open-source ruleset's documentation, written by humans, compares to an LLM's documentation of the same ruleset given only the rule syntax.
The results yield more questions than answers, at least for me. He measured the overlap of investigative steps per rule between humans and LLMs, ranging from 40% to 55%! Gary eloquently points out that it doesn't really say whether playbooks are better or worse between humans and machines.
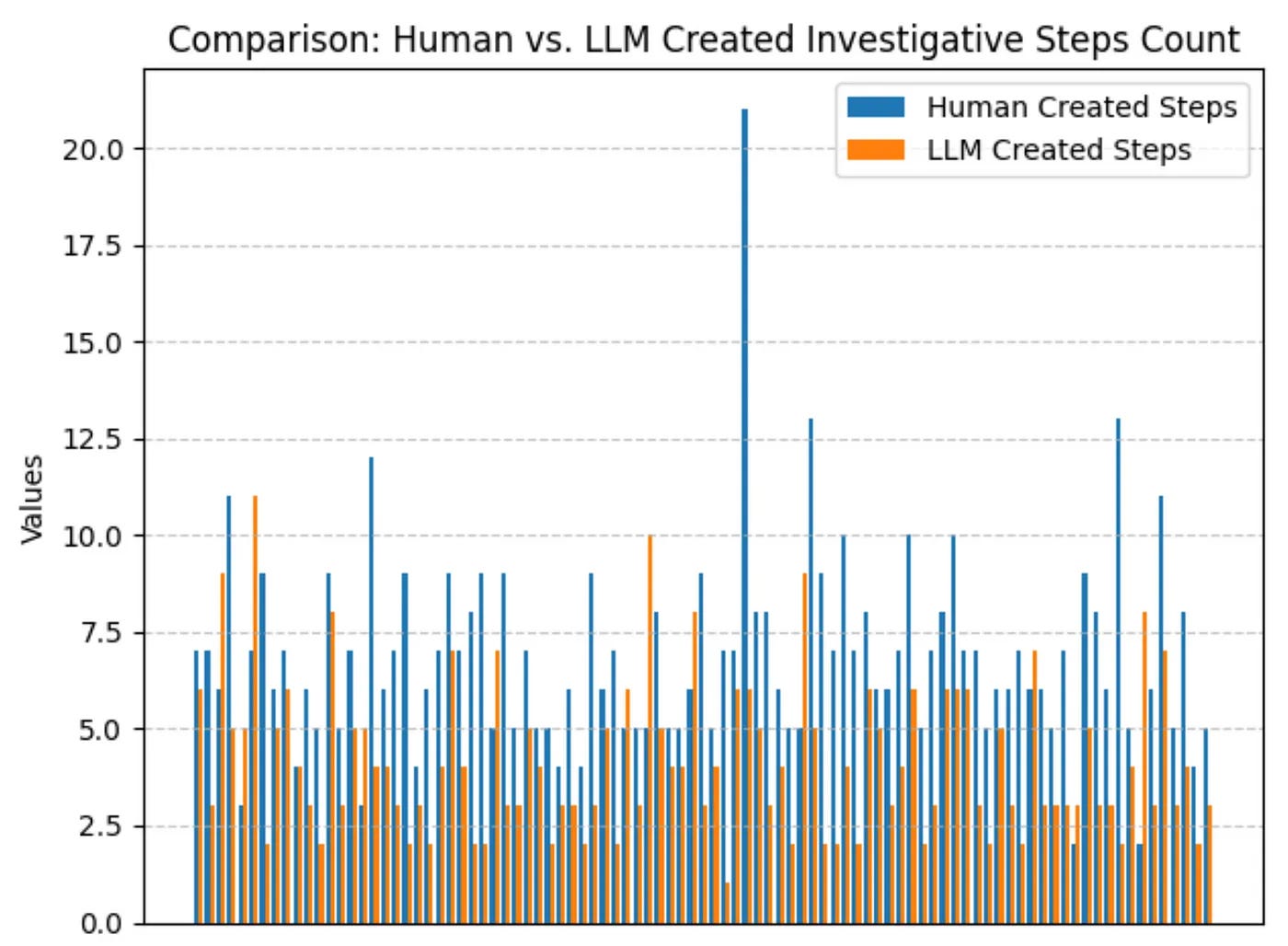
Elastic's ruleset is tailored for their products and not individual environments, so it's hard to say whether these playbooks make sense in a specific SOC scenario. Two, playbooks can contain generic and non-generic instructions. An example is "Open Workday and confirm XYZ's workstation is within the Finance subnet" versus "Correlate IP addresses with threat intel." Are these helpful steps or not useful? Again, it depends on the environment!
The more I dive into LLMs for security, the more it becomes apparent that you'll be disappointed without anything tailored to your environment. Gary puts a call to action at the end of the post for running his open-source toolset against your ruleset to see how it performs against his benchmarks. He asks the community to send him the results if you can so he can do a follow-up post.
May 7 Issue
Building Own MCP - Augmented LLM for Threat Hunting by Eito Tamura
This is the most comprehensive threat model I've seen for MCP servers since they entered the zeitgeist of developers and security. If you aren't familiar with MCP servers, LLMs, or AI in general, Tamura provides an excellent introduction at the beginning of the post and increases technical details. There are a ton of risky attack surfaces between client and server, and it's wild to me that an MCP can answer your questions that may result in arbitrary code execution.

The blog doesn't stop there, though! After reviewing the MCP threat model, Tamura helps readers set up an MCP lab environment for threat hunting and log analysis. Part 2 of the blog is about setting up the architecture, which includes an ELK stack plus its MCP server, a local Claude with an MCP client, and a vibe-coded custom MCP server to contact threat intelligence sources.
Part 3 is MCP's threat emulation and testing for hunting and analysis. I'm surprised at how well it did with (minimal) investment from Tamura. You see a ton of startups doing "AI SOC" analysts for this specific scenario, and although they look prettier than Tamura's setup, the outputs generally look the same. He went over three scenarios: investigating mimikatz telemetry, a malicious file being downloaded, and some log analysis.