

Det. Eng. Weekly #114 - I thought that I was dreamin' when you said its a SEV-1
I had no chance to prepare, I couldn't see it comin

Welcome to Issue #114 of Detection Engineering Weekly! It feels good to be back; I definitely needed the week off :).
Some real talk: a lot of people ask me how they can send over blog posts they're working on or want to discuss Detection Engineering with me. It’s a highly privileged position to be in, as I receive many great messages, but I struggle to keep up with LinkedIn, email, and Substack. So, I figured I’d engage with you all again using my own LinkedIn page for the newsletter.
https://www.linkedin.com/groups/13266114/
So, please come hang out and Follow the page for a much better engagement model with me and with all the subscribers and readers of this newsletter. I will be conducting Q&As, posting interesting articles and questions, and actively reading for new content.
I have a few other plans, such as videos or longer-form posts, that’ll be exclusive to them. So stay tuned!
Here’s the link: https://www.linkedin.com/groups/13266114/
📣 Datadog Detect Conference: TOMORROW!
Tomorrow, May 29, is the Datadog Detect conference! We have some fantastic speakers talking all things Detection Engineering. And I couldn’t be more excited to say we’ve crossed to over 1100 registrants tuning in to watch!
So, do y’all wanna hang out? It’s tomorrow, May 29, at 12:00 p.m. ET. I’ll be kicking off with opening remarks, and we'll dive into four technical talks on detection engineering.
Click here to register 👉 http://bit.ly/datadog-detect
~ Note ~ This is my employer, and with this current iteration, we do require a form sign up. Feel free to sign up / unsub, but you might have to wait until after the con.
⏪ Did you miss the previous issues? I'm sure you wouldn't, but JUST in case:

![Det. Eng. Weekly #112 - ]ffcvbhvvji90](https://substackcdn.com/image/fetch/$s_!dfFN!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F81ae37c5-93a3-4bc0-a87d-883a600b3c37_705x486.png)
💎 Detection Engineering Gem 💎
Why is no one talking about maintenance in detection engineering? by Agapios Tsolakis
This “restoring focus” blog from Tsolakis provides a candid and insightful examination of the state of detection engineering from a rule maintenance perspective. The detection lifecycle’s fun part (IMHO) is on the right side of the equation, aka the blue circles (shoutout to Detection GOAT Haider Dost)
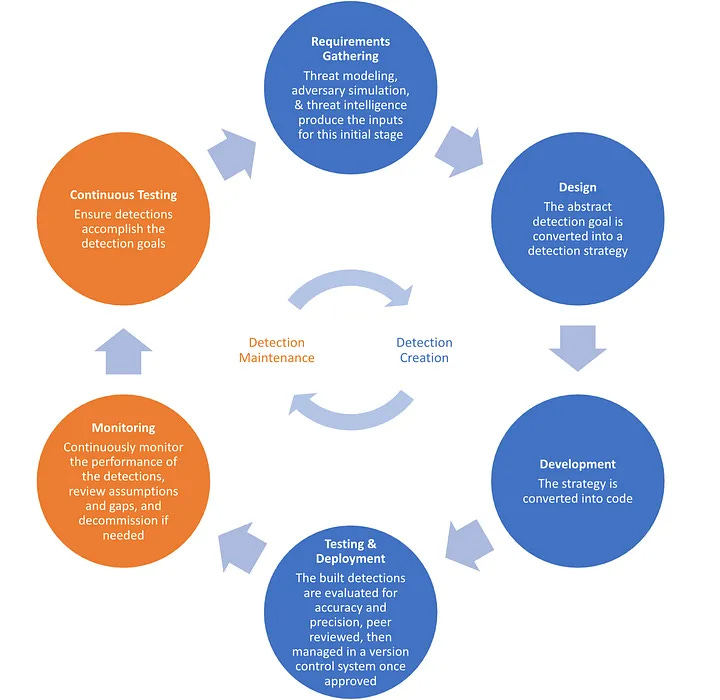
The not-so-fun part is the orange circles on the left. However, according to Tsolakis, and I concur with him, this is one of the most critical parts of our job. The curation and maintenance of rules keep them resilient and reduce costs in the long run. This model doesn’t necessarily address the types of maintenance other than “performance.” So, what is maintenance exactly?
I harp a lot on how security steals concepts from software engineering and that it should steal concepts because it works really well. So, Tsolakis draws inspiration from the idea of software maintenance. This seems like “boring, low-skilled work,” but whenever someone tells me that work is tedious, I tend to believe it’s some of the most important work to do.
The best part of this blog is mapping maintenance categories to detection engineering. Basically, there are four: corrective, adaptive, perfective, and preventive. Corrective is probably the closest thing we all work on because it’s the false positive problem and is reactive. The other three are mostly proactive types of maintenance, and he argues we don’t invest enough time in them.
Go check out his descriptions of the latter three as they relate to detection rules. I’m excited to see the following blogs in this series!
🔬 State of the Art
Cloud Incident Readiness: Critical infrastructure for cloud incident response by Invictus Incident Response
This is Part 3 of Invictus’ series on Cloud Incident Readiness, and it’s a standout for several reasons. I LOVE the framing of Incident Readiness because, many times, we get lost in the sauce of log sources, detection coverage, and metrics like MTTR/MTTD. These are all great, don’t get me wrong, but how much of this matters as a measure of health in the event of an incident?
Invictus has a great take on part 3, which is the infrastructure required for cloud incident response. They review each cloud and discuss the relevant cloud-native technologies necessary to perform these functions, allowing you to prioritize containment and forensics afterward. I appreciate the governance advice on their recommendations, so the idea is to offload sensitive security data to separate accounts or subscriptions to prevent tampering and custody requirements.
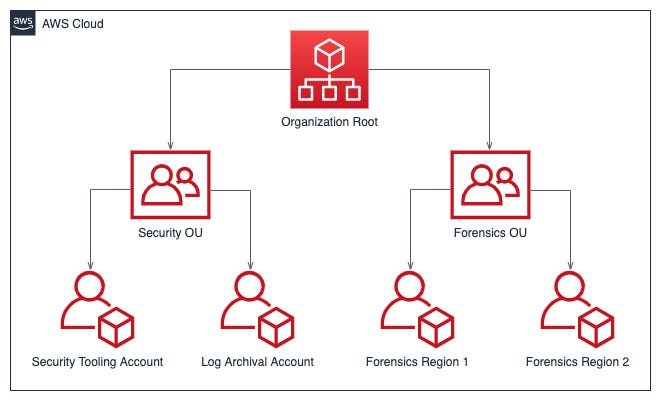
For example, they link to the AWS Incident Response guide for best practices on how to do this for AWS-native firms. Essentially, you can set up different organizations to offload data for forensics after the fact, log archiving for auditing and alerting, and your tooling accounts to assume a role in other owned AWS organizations to perform scanning.
Detection Pitfalls You Might Be Sleeping On by Daniel Koifman
Operating Systems were a mistake. No, but seriously, this blog post showcases how peculiar some of the implementations of operating system fundamentals can screw with threat detection. And it’s not just picking on Windows; Linux has some weird stuff, too. And it’s not odd when you put the lens on of a developer or a system administrator.
I’m not saying all of this because I think I could’ve done better; it’s quite the opposite. These are complex ecosystems with years of development, trade-offs in backward compatibility, and millions of lines of code. Of course, threat actors find ways to evade detection. S
I just want to apologize TO ABSOLUTELY NO ONE, because I’m still making fun of crazy OS peculiarities like:
Some binaries, like
ipconfig,net.exe, andnet1.exe, insert two spaces in the command line. So a detection rule that looks for a process that is affected by this issue with a single space in the parameter — will fail.
Stay frosty out there, my fellow detection aficionados.
Detection Response by tracing File Lineage with KQL Queries by Sergio Albea
Blocking and detecting malicious file execution should be the core of what many of us do on a day-to-day basis. It’s the best way for us to demonstrate that malware managed to bypass our security controls and ultimately compromise a system. Luckily, we caught it before it did damage. But what about the way these files got there in the first place?
Albea’s post provides several detection opportunities and rules to answer this question. The two scenarios he covers include grouping by the unique process IDs that initially dropped the files and adding forensic enrichment to a malicious file to determine whether it originated from a compressed file or a URL. Albea cleverly calls this “file lineage,” I’m stealing that one for later.
How to Guarantee Your Red Team Will Fail by 0xdade
I read a ton of content about how to build a successful “X.” Building a successful rule, a detection team, or a successful career.. but this is probably one of the first times I’ve read something in the opposite vein of success: failure!
Dade is a renowned red teamer, and his post here discusses all the ways you can set a red team up for failure. This type of blog helps me as a manager because it identifies red flags that can be recognized quickly before these issues fester. My favorite section is "Emphasize technical superiority” because it prioritizes being more intelligent than everyone and giving special treatment to red teamers rather than enabling them to leverage their skills for good.
Offensive Threat Intelligence by Andy Gill
Red teamers make the best detection engineers and CTI professionals. Truly, they do. They tend to evolve the fastest to the latest techniques and technologies, and you can throw a red team into any unknown environment. You can trust they can quickly figure things out and understand their surroundings. The pitfall with red teamers is what 0xdade wrote in the blog above. You can internalize his points or see how managers can mess this up, but the outcomes are the same.
How 0xdade wrote about how red teams fail, Gill writes about how red teams can succeed by implementing threat-informed defense alongside blue teamers. Tradecraft is an art; sometimes, holding onto your warez and malware is easy. Still, if you aren’t emulating how adversaries target your environment, you miss a huge opportunity to make an impact.
I love Gill’s approach here. He argues that CTI can serve as an input and an output of a red team. By working closely with an intelligence team or emulating one yourself, you can effectively cover a wide range of detection opportunities, from insider threats to opportunistic criminals.
☣️ Threat Landscape
Operation ENDGAME strikes again: the ransomware kill chain broken at its source by Europol
Europol takes down infrastructure connected to seven different malware families. These families, such as DanaBot and Bumblebee, are initial access malware. Once a victim is infected, initial access brokers sell access to high-value targets to ransomware operators, who then run a playbook to ransomware victims and split the loot.
Authorities added 18 suspected operators to the EU’s most wanted list, so these crews will probably not be able to vacation in Ibiza for the time being.
Advisory Update on Cyber Threat Activity Targeting Commvault’s SaaS Cloud Application (Metallic) by CISA
Commvault, an enterprise SaaS app that helps organizations backup critical files and services, was targeted by threat actors to potentially access their customer environments. Based on the writeup by CISA, threat actors targeted and may have accessed backup files (lol) in their Azure environment, which exposed customer secrets to victim M365 accounts.
How the Signal Knockoff App TeleMessage Got Hacked in 20 Minutes by Micah Lee
This is Lee’s WIRED write-up on how the Signal backup service, Telemessage, was pwned in about 20 minutes. Through some good ol’ internet scanning dumpster diving, specifically with DNS, Lee (presumably the original hacker) found an exposed endpoint that generated a Java heap dump and contained credentials and plaintext chat logs. It shows that a massive hack like this can stem from simple misconfigurations rather than uber haxxing techniques.
Protecting Our Customers - Standing Up to Extortionists by Coinbase
I wish I could have posted this during my week off, but it’s still worth a read, even though after a week, things become old news. Coinbase suffered a data breach (with a subsequent 8-K filing) and wrote a post on some of the technical details behind it. Extortionists paid off some insiders at Coinbase for access to data took the data and tried to extort the crypto firm in return.
This post is a masterclass in transparency regarding security incidents. It’s concise and brief, including various recommendations for customers to protect themselves. They included a 20 million dollar reward fund for information leading to the extortionist’s arrest. How baller is that?
🔗 Open Source
raphabot/awesome-cybersecurity-agentic-ai
Yet another awesome-* repo, this one indexes a bunch of cybersecurity-based agentic resources. They split these up by MCP servers, research agents, tools, frameworks and datasets.
sharpeye is an open-source Linux intrusion detection and threat hunting project. You build and run a binary across 13 modules that hunt for all kinds of fun Linux threats. It features a machine learning module for enhanced detection capabilities.
zip_smuggling is a data exfiltration and pseudo-steganographic tool for hiding data within Zip archives. You run the tool and point to “important data” in the command line, along with benign data, and it creates the archive. By manipulating offsets inside the Zip directory listing, you can’t tell there is hidden data unless you rerun this tool.
shankar0123/network-observability-platform
Open-source ThousandEyes alternative for network observability. It’s a pretty massive project to compete with ThousandEyes. You can do some crazy stuff, like BGP analysis and network canaries, to visualize changes in a network topology before deployment.
Proof-of-concept MCP server with built-in malware analysis capabilities from FLOSS/UPX/CAPA/YARA. You issue prompts to the server and it’ll run these binaries on the backend and output back to your prompt.