

DEW #152 - Celebrating Gaps in Detection Coverage, Threat Hunting on Teams & OpenAI Axios post-mortem
rain rain go away~
Welcome to Issue #152 of Detection Engineering Weekly!
✍️ Musings from the life of Zack:
The sun is staying out later and coming up earlier. There’s nothing better to me than an early morning sunrise :)
I finished my book about the Marquis de Lafayette, Between Two Worlds, and it was fantastic. I’m already reading a new one about the ugly truths of living on Mars called A City On Mars. A former NASA Chief Economist recommended it on a podcast
I’m excited for an upcoming beach vacation in the Caribbean for some much-needed sun and relaxation. I’ll still be putting an issue out, so there won’t be a gap in coverage (ha)
Sponsor: Adaptive Security
Can Your Team Spot an AI Deepfake Attack?
Today's phishing attacks involve AI voices, videos, and deepfakes of company executives.
Adaptive Security is the first security awareness platform built to stop AI-powered social engineering.
Adaptive protects your team with:
AI-driven risk scoring that reveals what attackers can learn from public data
Deepfake attack simulations featuring your own executives
Interactive, customizable training content
💎 Detection Engineering Gem 💎
Measuring What We’re Missing by George Chen
In this post, Chen gives readers some honest thoughts and super reasonable metrics around measuring detection efficacy. We tend to fall into the true-positive/false-positive trap because they are the easiest to measure and explain. False negatives are the most risky, but if you only rely on a security incident where an alert failed to fire, they can really affect your detection engineering operations, because you can only measure when things go wrong. Your operational work should revolve around identifying coverage gaps (false negatives) and eliminating unnecessary work (false positives).
These metrics can fall into “busy work”, when you really want to show impact. You also risk making your coverage gaps harm your operational score instead of celebrating them.
Chen’s fix is to separate detection efficacy into two signals:
An effectiveness score (how well do tested controls perform?)
A discovery count (how many new gaps did you find outside of testing?)
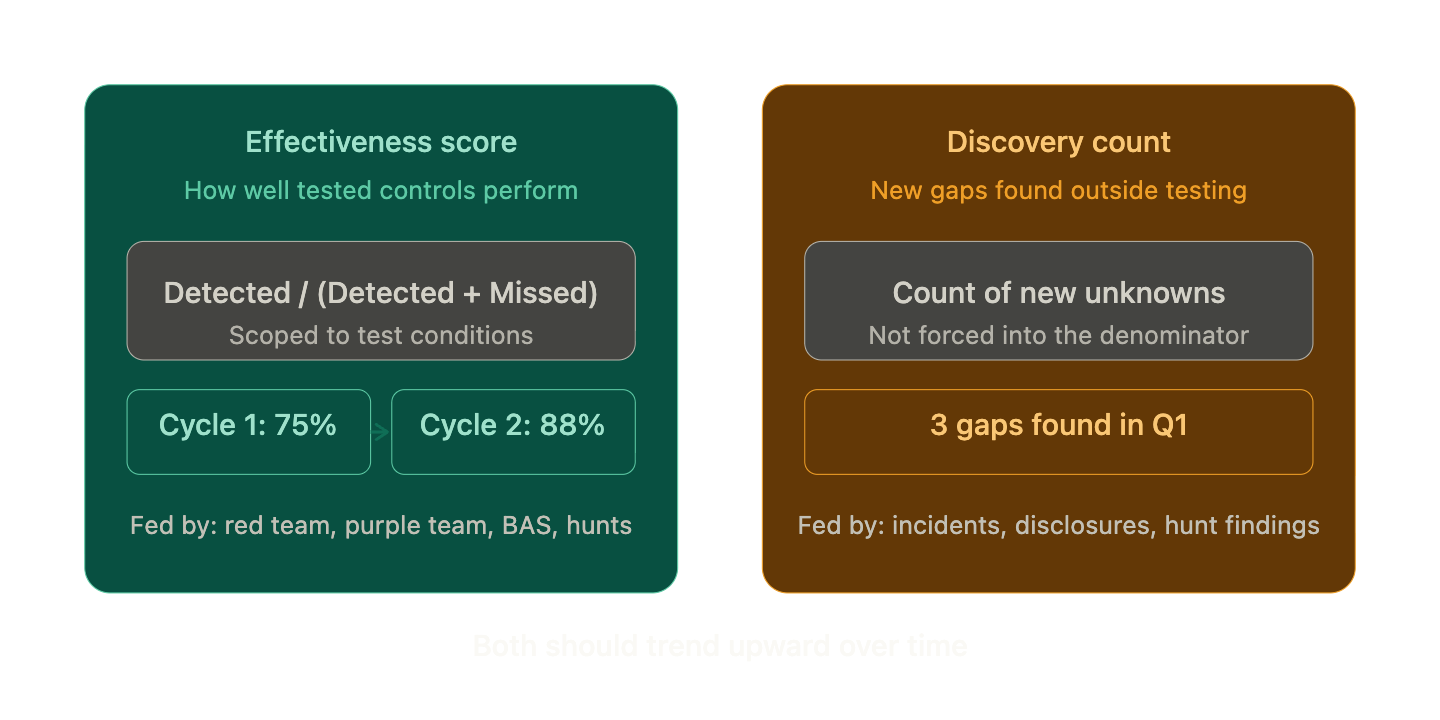
The “under test conditions” qualifier is the important part. This isn’t a coverage number. It’s a performance number scoped to what you’ve actually challenged through red teams, purple teams, BAS, and threat hunts. If 50 techniques are executed and 10 are missed, you now have a denominator, a defined scope, and a measurable gap. Without that structure, a miss is just an observation.
The discovery count stays separate on purpose. If you lump newly found gaps into the denominator, the more unknowns you surface, the worse your score looks. That creates a perverse incentive where teams stop looking for blind spots because finding them risks tanking the metric. Chen’s answer is simple: keep it as a standalone count. “3 new gaps discovered and addressed in Identity & Access this quarter.” Effectiveness tells you how well tested controls perform. Discovery tells you how much you’re still missing.
I’m seeing metrics like this more often in security operations, where we’re starting to describe the health of the system, similar to what Site Reliability Engineering departments do. Chasing 100% accuracy is meaningless due to the Precision and Recall Problem, but showing any kinks in the armor can come across as unpreparedness. Owning the idea that you need to curate and maintain a ruleset, just like you maintain a cloud or on-prem environment, is a more stable approach for your sanity and for business outcomes.
🔬 State of the Art
Hunting Malicious Teams Delivered Links via Endpoint & Cloud Telemetry Correlation by CipherSecy
This comprehensive threat hunting report highlights a rare but effective attack scenario around Microsoft Teams. In any modern workspace chat application, you can talk with your coworkers and external people like contractors, vendors, or customers. So, something like Teams or Slack can serve as an excellent pivot point for threat actors, since they gain direct access to your DMs, and the telemetry isn’t as well-documented as with phishing emails.
CipherSecy built the following hypothesis before their hunt:
A compromised third-party account sends a malicious link via Microsoft Teams with the intent of compromising an internal user’s identity.
What follows are their findings and documentation on available telemetry to help catch these types of attacks via Teams. A hunt like this uncovers a ton of nuances and peculiarities in the attack flow from a visibility perspective:
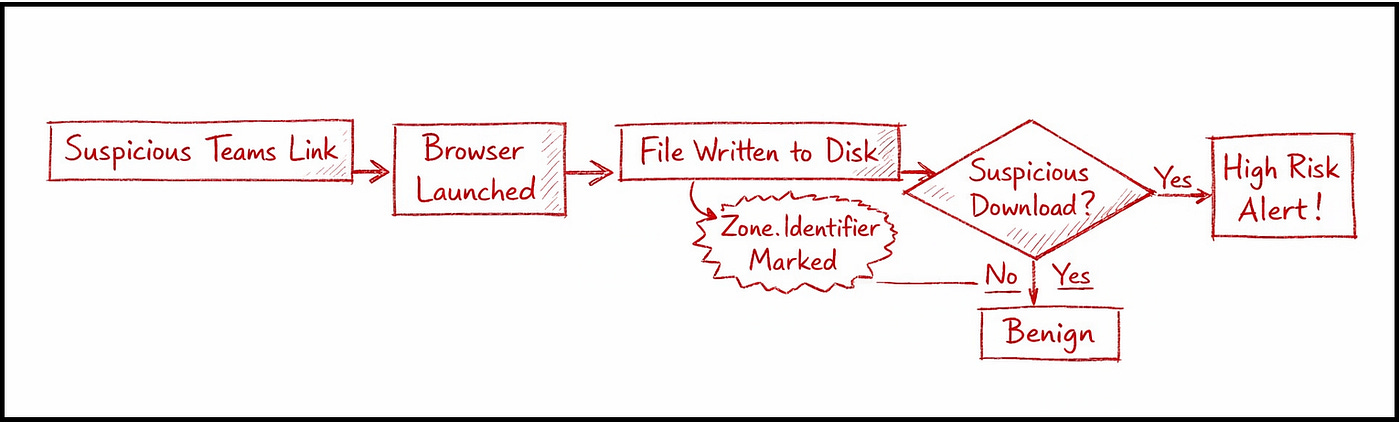
Teams launches an in-app browser via a CLI command. The browser can link to malicious downloads or phishing sites, so making sure you have an EDR that can provide that telemetry is important. The cool part here IMHO is the rich context from within the CLI command:
C:\Program Files (x86) \Microsoft\Edge\Application\msedge.exe"
--single-argument microsoft-edge:///?url=https://github.com/notsosafelink&
source=teams&treatment=4445&form=MY02BU&qpc=955403648535
&oid=<RCV-OBJ-ID>&hubappid=bc25fcef-8964-4e72-8287-23e2b496c128
&hubappsubpath=embed-client/chats/19:<SNDR-OBJ-ID>_<RCV-OBJ-ID>@unq.gbl.spaces
/view&hubappparams=hostCtx=edge&layout=singlePane&src=teamsLink
&messageId=<MSG-ID>&oid=<USER-OBJ-ID>&loginHint=<RCV-UPN>
&startTimeStamp=1773993512074&correlationId=<GUID>
CipherSecy points out two things here. One, —-single-argument indicates a process spawned Edge programmatically, which helps reduce the noise of manual browsing. Secondly, src=teamsLink means it was spawned from Teams itself. Both turn into high-value signals, and throughout the rest of the post, they show some of their KQL queries to perform additional hunting and inspire some detection opportunities.
Mythos has been the talk of the town since its preview release on April 7. The industry reacted to the hype with mixed reactions. On the hype side, it’s an extremely impressive model and deserves its accolades for vulnerability research and exploitation. In fact, Anthropic is worried enough about the model that it created an invite-only program, dubbed Glasswing, to give early access to companies that will initially use it to find and fix vulnerabilities.
On the other hand, the incentive structure of frontier labs like Anthropic is to build hype and generate buzz. And when you generate buzz around the security industry, you will get pushback against the hype, whether you want it or not. I believe Saxe’s pushback in this article has the best-grounded arguments to help us brace for impact without burning too much energy bracing too hard.
Mythos, much like Opus’ release, will fundamentally change a lot of our capabilities. But much like Opus, our security capacity is bounded by more than just computation and prompting. Saxe frames this argument with a thought experiment. If these frontier models changed the game for synthetic voice and text, have we meaningfully seen an explosion of activity in social engineering and phishing attacks? The key here is “explosion”, because that’s what it seems like the Mythos release is warning the industry about, but instead of phishing, it’s vulnerabilities.
I do wish there were some investigation from Anthropic on the detection and response front. Mythos will clearly help the vulnerability side of the house, but what about deep investigations, rule writing, or threat hunting? Frontier models have fundamentally changed blue team operations in these fronts, but I don’t think it’s ruined the status quo. We’ve certainly become better prompt engineers, though :).
Myth & Mythos: Where Do We Go From Here? by Joe Slowik
It’s pretty apt that Joe Slowik wrote a blog about Mythos on his blog named “Stranded on Pylos”. I really enjoyed reading this essay, mostly because it highlighted some of the intentional or unintentional decisions Anthropic made when announcing Project Glasswing. Specifically, the lack of non-American companies and the focus on tech & IT rather than critical infrastructure or healthcare organizations.
Joe is a staunch advocate for critical infrastructure security research, especially around OT systems. He offered a critical but fair take on the initial release of Project Glasswing, lacking any focus on these areas. In all fairness, as he points out, many of these large tech companies do build and maintain products for critical infrastructure networks, but there isn’t enough information from Anthropic to confirm whether they are considering the threat model for these networks.
Admittedly, I think it’s a Catch-22. If Anthropic brought in a Siemens, and maybe didn’t bring in Apple, would we be making the same argument? Probably. And the marketing is well done, capturing the attention of major news outlets worldwide. Though Anthropic, in my opinion, has done the most to demonstrate its commitment to AI safety research, I feel like they are more trustworthy for the time being, especially when they say something is “too dangerous right now.”
Webex-ploitation by Grumpy Goose Labs
I first featured Grumpy Goose Labs in Issue 11 (!!), and since then, they’ve done a ton of research on hunting for Fake IT Workers. In Issue 138, I wrote an analysis of their fantastic research on hunting for KVM Switches in Crowdstrike, which can be a great signal for facilitators who gain fraudulent employment. In this post, they switch their hunting methods to look for Webex sessions used by facilitators in a similar way.
I find it insane how RMM software, like Webex, has poor audit logs, logs everything locally, and provides opaque logs that make it a lot harder to detect and hunt for this activity. I ran a cursory search on GitHub for any log-shipping pipelines that parse, normalize, and ship these logs to providers, and I didn’t find any.
The craziest find in this research is how WebEx has keylogging capabilities. It’ll record keyboard firing events to the local log files, and so theoretically you can: a) spy on your employees, b) run malware that ships these logs off to a C2 for password collection, or c) hunt for TTPs by some of these IT Workers.
☣️ Threat Landscape
Our response to the Axios developer tool compromise by OpenAI Security
The OpenAI Security team published a security update on the impact of the Axios supply-chain compromise on their macOS signing process. According to their security team, the GitHub action that signs the binaries for their macOS apps, such as Codex CLI and ChatGPT desktop, was compromised and downloaded the malicious Axiox 1.14.1 version.
Based on research published over the last week and a half, many of these compromised builds failed due to peculiarities in their code, but OpenAI revoked and rotated the signing certificate out of an abundance of caution.
Tracking Adversaries: EvilCorp, the RansomHub affiliate by Will ‘BushidoToken’ Thomas
Following my Threat Landscape coverage from last week’s issue, threat research G.O.A.T. BushidoToken’s timely issue on EvilCorp helps tie their operations under the newer and active RansomHub affiliate program. Since the U.S. sanctioned EvilCorp, it has become much harder for victims to pay the group after they suffer a ransomware attack. This leads groups to rebrand as new groups or join affiliate programs to continue their operations, removing a significant financial hurdle to their success.
Will’s survey of infections from the last few years of ransomware attacks helps tie them to EvilCorp because of the use of the SocGolish malware. This is about as close as you can get to attribution with only pure technical data without relying on HUMINT, such as law enforcement or doxxing.
Inside an AI‑enabled device code phishing campaign by Microsoft Defender Research Team
This post by Microsoft Defender Research highlights a phishing operation tracked under the EvilTokens phishing group. It focuses on DeviceCode phishing, where a threat actor abuses an authentication flow primarily used to sign in to Microsoft accounts associated with non-endpoint applications, such as Netflix or YouTube. The way the attack works is when you click “Sign-in with Microsoft”, you are given a token that lasts 15 minutes to complete the authentication flow. This makes sense given it’s designed for devices other than your laptop.
Traditional phishing campaigns must generate the token before sending a phishing email, which can limit the infection window. According to Microsoft, EvilTokens' unique approach is to use AI-generated frontends and workflows to create on-the-fly tokens via a hyper-optimized phishing page, thereby extending the window to the full 15 minutes, since tokens are generated only when the victim interacts with the attacker's infrastructure.
Tracking an OtterCookie Infostealer Campaign Across npm by Alessandra Rizzo
In the latest evolution of Contagious Interview/WageMole and FAMOUSCHOLLIMA-aligned threat actors, Panther security researcher Alesandra Rizzo tracks an open-source supply chain attack that results in an OtterCookie infection, followed by the exfiltration of developer secrets and machine configuration files. To me, there are two interesting findings that showcase the evolution of DPRK-nexus threat actors.
First, they are heavily abusing Vercel services, making it easy to stand up and rotate attacker infrastructure used as exfiltration points. Secondly, the OPSEC trickery around dotted Gmail email addresses, such as t.e.ch.y@detectionengineering.net, allows them to get a little more use out of the emails, since Gmail ignores dots when receiving email on behalf of users, whereas other services like npm do not.
ClickFix technique uses Script Editor instead of Terminal on macOS by Jamf Threat Labs
When I first learned about the ClickFix infection technique, I couldn’t believe that people would copy and paste terminal commands from a website into their Terminal. I scoffed at people falling victim to it, exclaiming that it would never happen to me because I’m a security person. I then proceeded to install a package manager by copy pasting a bash command into my terminal:

The technique works because the industry has collectively settled on the ease of installing software via a copy-paste command. So, as vendors like Jamf and Apple began to catch up by deploying mechanisms to detect this behavior, threat actors adjust and continue the cat-and-mouse game.
In this post, Jamf Threat Labs uncovers a ClickFix campaign they discovered that combined the social-engineering aspect of a lookalike website with an older technique: AppleScript URIs. According to the researchers, victims are presented with the phishing website, and instead of copy-pasting the command, you click an Execute Button, which runs a native applescript:// feature that launches a Script Editor and prompts the user to run it.
The payload leads to an infostealer infection so not much changes there, but adjusting the delivery and exploiting the trust of victims running these commands are just one UI/UX workflow away from a new infection.
🔗 Open Source
salesforce/url-content-auditor
url-content-auditor scans web content for sensitive data, such as secrets and PII, as well as anything that puts the website's or its users' privacy at risk. It’s smart enough to download video, audio, and documents, extract data, apply some heuristics, and also use LLMs to classify and alert on anything sensitive.
Modern static and dynamic analysis toolset for malware analysis. It has an impressive number of analysis engines, including Windows, macOS, Linux, Android, and iOS. It uses a Docker sandbox for its dynamic analysis, so it’s pretty lightweight. It generates findings in the console, JSON, HTML, and SARIF for CI/CD pipeline reports.
DeepZero is a research toolset using quite a grab bag of techniques to find vulnerabilities in Windows kernel drivers. Two features stood out to me. One, it uses Semgrep rules on decompiled binaries to find “known vulnerability shapes”, which essentially means it can direct analysis towards interesting findings versus sweeping the whole binary. On the back of the Mythos announcement, it uses DeepAgents from langchain and Vertex AI to triage the Semgrep findings.
Massive compendium of HackTheBox writeups used for self-learning and exploration. This is super helpful for those who want to explore topics as they work through HackTheBox challenges, or they want to see and read about techniques used during these challenges. It has four interactive tools you can use to query and generate write-ups based on your interests: everything from searching for specific machines, operating systems, and attack paths to a Skill tree that maps out your learning journey.
Slick-looking syscall tracer leveraging eBPF versus strace’s ptrace. This is especially helpful if you are using it to research malware or hunt for vulnerabilities in binaries on CTFs. The TUI is quite beautiful and interactive, whereas strace makes me want to cry every time I stare at it.