

DEW #147 - Flying Blind with your Logs, MAD lads and Z-scores & How Reddit Does Threat Detection
I need a beach vacation asap

Welcome to Issue #147 of Detection Engineering Weekly!
✍️ Musings from the life of Zack:
Sickness in the Allen household was rampant all last week until today. Fingers crossed that the family stays healthy because there is FINALLY some good weather in New England to look forward to
I recently bought a history book about the Marquis de Lafayette. It’s been so nice to get away from technical books and even fantasy to enjoy some history. This guy was a baller and essentially helped overthrow two governments and turn them into democracies
BSidesSF is getting closer and I’m getting more and more excited to enjoy a security conference and network. There’s a chance I’ll be bringing stickers :D
Sponsor: Cotool
Cotool Research: Benchmarking LLMs for Defensive Security
Most AI benchmarks skew toward offense, so we built our own grounded in real SecOps workflows to answer questions that matter in production:
Which model should power your triage agent?
What architectures hold up in complex investigations?
We believe those answers should be public, so we release every benchmark we create.
💎 Detection Engineering Gem 💎
You’re Probably Flying Blind by Lydia Graslie
The bane and boon of Cloud or SaaS technology is that it is managed by someone else. This business model has enabled some of the biggest businesses in the world worry about their core business, rather than building and maintaining bespoke software or procuring software that they must internally manage. “The olden days” involved running your own e-mail servers, databases, and Active Directory servers (though many folks still do this today). The problem, though, is that because it’s managed by someone else, you are at the whim of how they change the software, and the managed part becomes an operational risk if you don’t like that change.
Don’t worry, it gets worse for security teams. And Graslie’s blog helps frame this issue around security operations and detection rules. I’m glad she’s using Microsoft products as a grounding element for these issues because 1) they are fun to pick on and 2) they deserve every criticism due to their history of notorious licensing and product changes that lead to detection engineers “flying blind”.
Graslie lists out four intertwined issues with relying on SaaS and Cloud technologies for detection efficacy and here they are in my own words:
Detection availability and observability. Unlike a machine in your local network that you can walk over to and physically touch, you have to have awareness of the SaaS & cloud technologies, licenses and services that are in use. You have to hope that these products are functioning and sending the right logs and that there aren’t outages or delays in delivery
Multiple attack paths to the same outcome. Akin to how many Windows based attacks leverage intermediary or middleware APIs to prevent detection on certain attack paths, Cloud and SaaS attacks operate similarly. In fact, in many ways, they are their own operating systems, and achieving lateral movement or privilege escalation can happen in more than one way. Here’s a Mermaid Diagram I had Claude generate to demonstrate Graslie’s example of “same action, different telemetry paths” in this section:
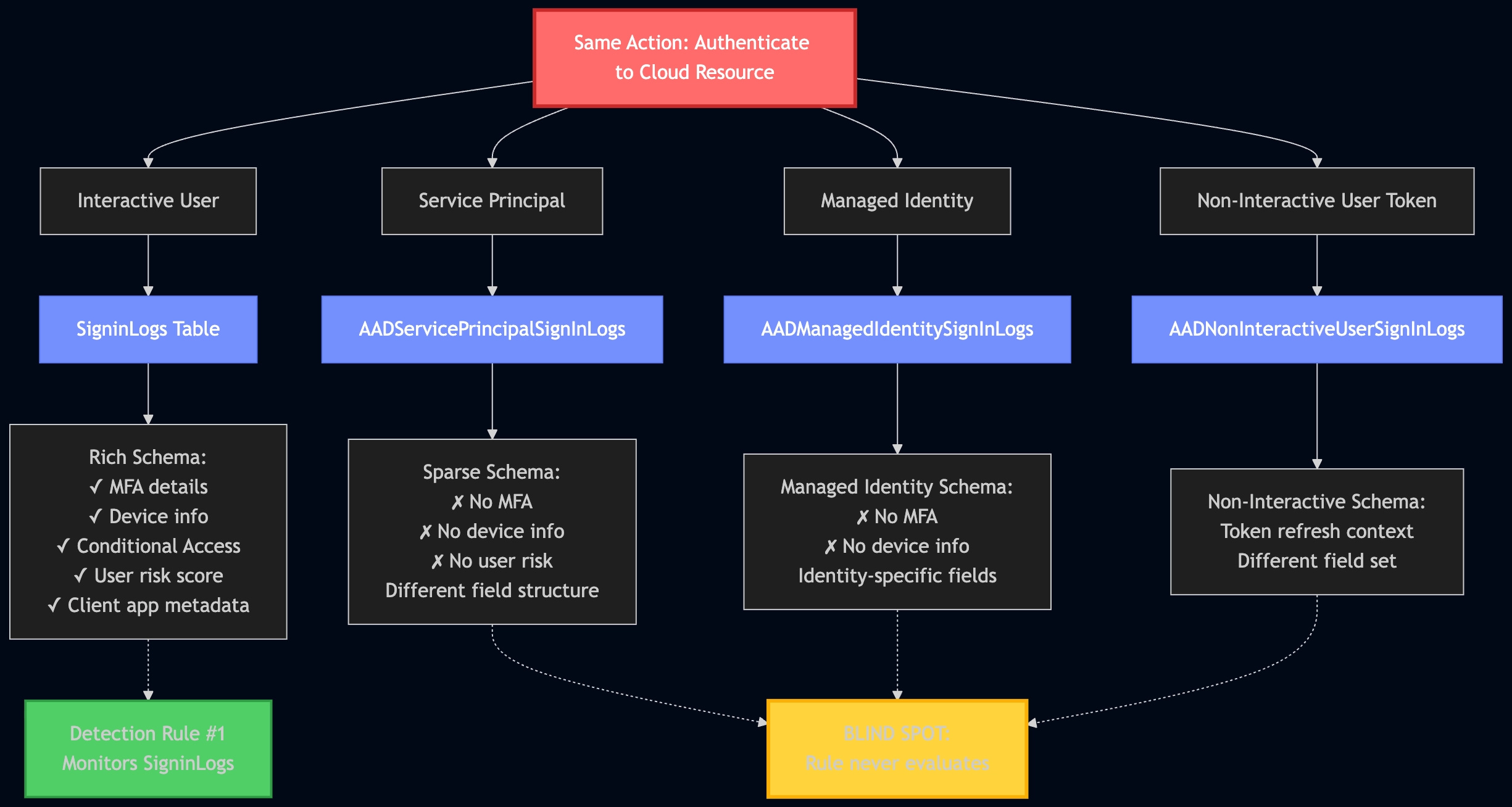
In this Azure example, Graslie explains how authenticating to a single cloud resource can take these four paths. An interactive user seems like a logical detection path, but the other three listed afterward do the same thing, and the source authenticating identity type, the logs, and the schema are all different.
Shifting attack surfaces, new and deprecated features, and pricing are a detection nightmare. She lists out an absolutely ridiculous timeline of Microsoft releasing “at least seven Microsoft PowerShell modules and protocols for managing identity”. That’s seven different API collections you need to account for to prevent Issue 2 listed above.
Similar to 3, the detection and observability surface shifts. A good example of this is when a field or value format changes in a log source you are writing detections over. This happens all the time with audit logs from SaaS vendors. New subproducts can force vendors to change field names or add new values that you’ve never seen before.
Each one of these issues is “intertwined.” Graslie gives several examples of how they can compound in certain scenarios. For example, how can you understand your attack surface if you don’t have telemetry, or even worse, you aren’t even aware that a SaaS app exists in your environment? She concludes the post with a teaser for a series that examines each of these four issues, all grounded in Microsoft environments.
🔬 State of the Art
The Detection Engineering Baseline: Statistical Methods (Part 2) by Brandon Lyons
This is Brandon’s Part 2 continuation of his “Detection Engineering Baseline Series.” It has a more practical application to the data he generated in Part 1. The key skill here is distribution mapping, typically referred to in our statistics class as the normal distribution or the Bell curve. I believe a lot of SOC analysts and detection engineers perform many of the techniques Lyons’ describes here without knowing it. For example, Group-Bying a field then sorting from Lowest → Highest shows “rare events”. Another example Lyons calls out is filtering out the noisiest offenders, such as service accounts, to reduce 80% of the signal so you can hunt through the remaining 20% a la The Pareto Principle.
I especially appreciated the commentary on the distribution of security data in general, as illustrated here:
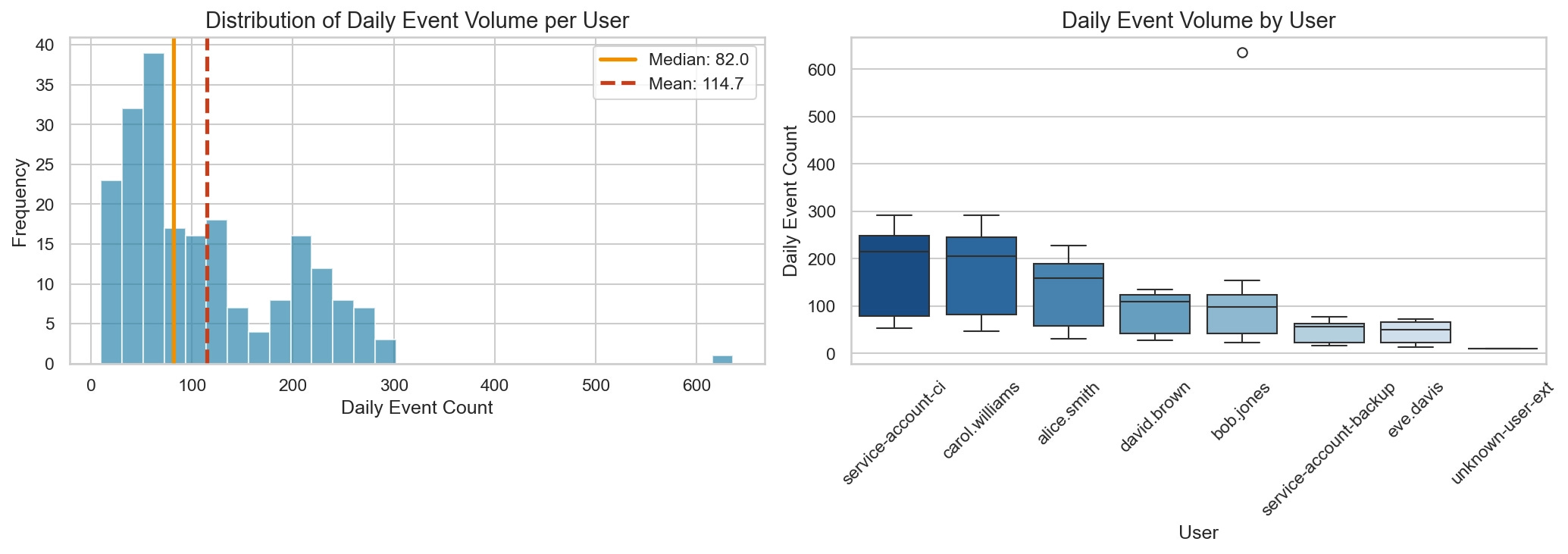
Unlike a normal Bell Curve, security data tends to have a long tail, according to Lyons. This makes baselining harder because you need to account for noisiness on both ends of the distribution in different ways. Lyons astutely points out that this is why typical mean and standard deviation calculations fall short of generating meaningful alerts here: a single shift in traffic, or a misconfiguration that throws off a ton of alerts, can completely screw up detection.
He then continues this analysis using Median Absolute Deviation (MAD) & modified Z-score, as explained in the first post, which helps maintain robustness in the case of wild value swings. The computation of MAD helps capture the position of a new value relative to a set of numbers, rather than its magnitude as it swings to either end of a distribution.
I took his example and wrote it out myself (with Claude helping with formatting) so I could understand it better:
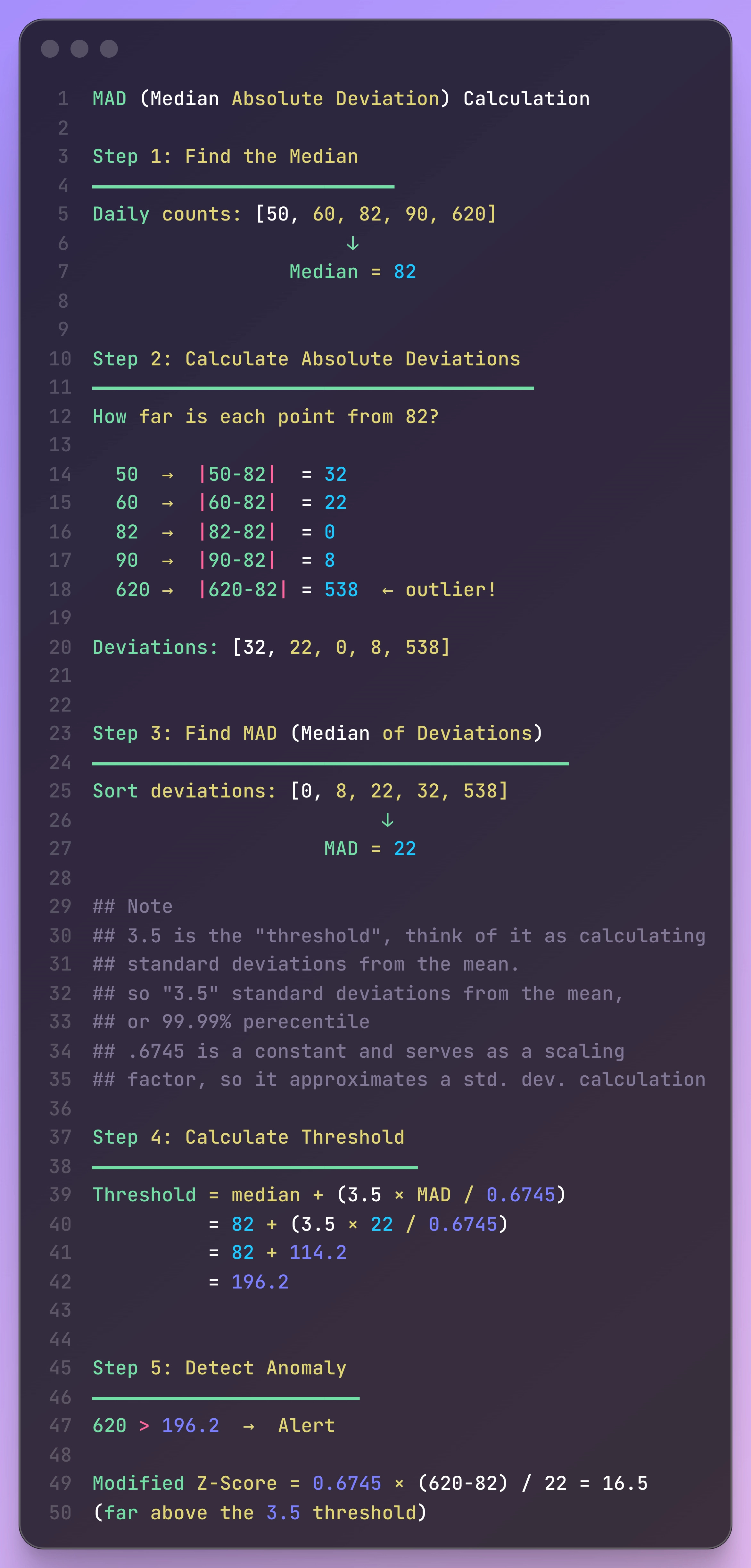
What makes this robust or resilient is that you may get a swing in Daily Counts (Line 5), much like you see 620, but it doesn’t skew the mean, as you are still focusing only on the median.
Once you get the hang of this, there are still ways to slice and dice your data to get a representative sample. Lyons calls out entities as an option, or cohorting, which lets you reconcile traffic or behavior down to individual users, service accounts, or services themselves. These “context dimensions” are important because they only really work in your environment, and your team should know the context for baselining better than any other security product.
How Reddit Does Threat Detection by Austin Jackson
I love reading posts describing how organizations design and execute their Security Operations programs. In this post, Reddit Staff Engineer Austin Jackson describes the company’s philosophy and technology stack around threat detection. It’s a continuation of their rip-and-replace of Splunk post, which I need to check out, perhaps for another issue. Basically, the team moved to a Data Lake approach using Big Query, and they run Apache Airflow for detection rules and alerting. There are some neat detection-as-code tricks they did here, and because the system is a lot more decoupled than a massive Splunk stack, they’ve gained a few advantages.
First, all of their detections are written in a simple YAML format. The Airflow runner kicks off on cron jobs and runs queries over BigQuery to generate alerts. Once an alert fires, they send results to Tines for additional orchestration and enrichment. Jackson had a special callout about sliding-window detections and avoiding missed telemetry. In a recent newsletter issue, I analyzed a topic in which a researcher leveraged Watermarking to address SaaS export gaps, and the same concept applies here, where a Watermark is used in a separate table. The detection engineer appends a clause at the end of their query to use the Watermark timestamp to prevent telemetry loss.
Jackson finishes the post detailing their scoring workflows in Tines, and I thought the most unique part of this section was the AI Triage component. Rather than trying to run a singular agent across all of their telemetry, detection engineers can ship a prompt inside the rule for Tines to run over it for additional enrichment, analysis and scoring.

AWS Incident Response: IAM Containment That Survives Eventual Consistency by Eduard Agavriloae
Eventual consistency is a pattern in large-scale systems, like the AWS cloud, where a change in state isn’t instantaneous, and it will take time for the state to be replicated across all of the systems you are working with. This makes sense: imagine a massive AWS account with several sub-accounts and regions, and you need to push a change out to configurations or identity permissions. You should expect the change to take effect after you issue your configuration changes, but you may not know that it takes time for these changes to propagate.
In AWS security incident response, you may have to deal with this as you follow standard playbooks to isolate accounts or principals. According to Agavriloae, this eventual consistency pattern creates an opportunity for attackers to recognize that an isolation is in progress and, if they have the right permissions, revert the change before the state is locked in. AWS IAM is very hard to use because multiple escalation paths can lead to the same outcome, so creating mechanisms to guarantee isolation can miss certain attack paths.
Agavriloae provides a solution to this eventual consistency problem by leveraging Service Control Policies at the organizational level, where only break-glass IR roles can remove the quarantine policy.
👊 Quick Hits
Cyber Threat Intelligence Framework by CERT EU
I’ve always found it fascinating how CERT teams, especially those that protect countries or allies, publish their internal processes and frameworks for citizens to study. In this framework by CERT EU, they introduce the concepts of Malicious Activities of Interest (MAIs) and Ecosystems. MAIs, to me, read like “observables” in the STIX context. I think the more unique introduction, though, is the concept of Ecosystems. We tend to have CTI teams that look at the breadth of attacks against their organizations, and it’s easy for them to determine whether they were targeted.
Ecosystems, according to CERT EU, rely on the victimology or targeting set of an MAI. It’s almost like a self-organized ISAC for all of their constituencies. Because the EU is more than just a country, it can specifically dive into how MAIs target not only other Member states, but also things like Sectors, Events, and much more.
AWS Threat Detection with Stratus RedTeam Series — MITRE ATT&CK Style — Execution (Part 1) by Soumyanil Biswas
This is a great “detection lab” post that leverages my colleague Christophe Tafani Dereeper’s Stratus Red Team tool for threat emulation and detection validation in AWS. Biswas helps readers set up an AWS environment, configure the Stratus Red Team, configure data sources (CloudTrail), and eventually write a SQL and Sigma rule to catch each attack.
☣️ Threat Landscape
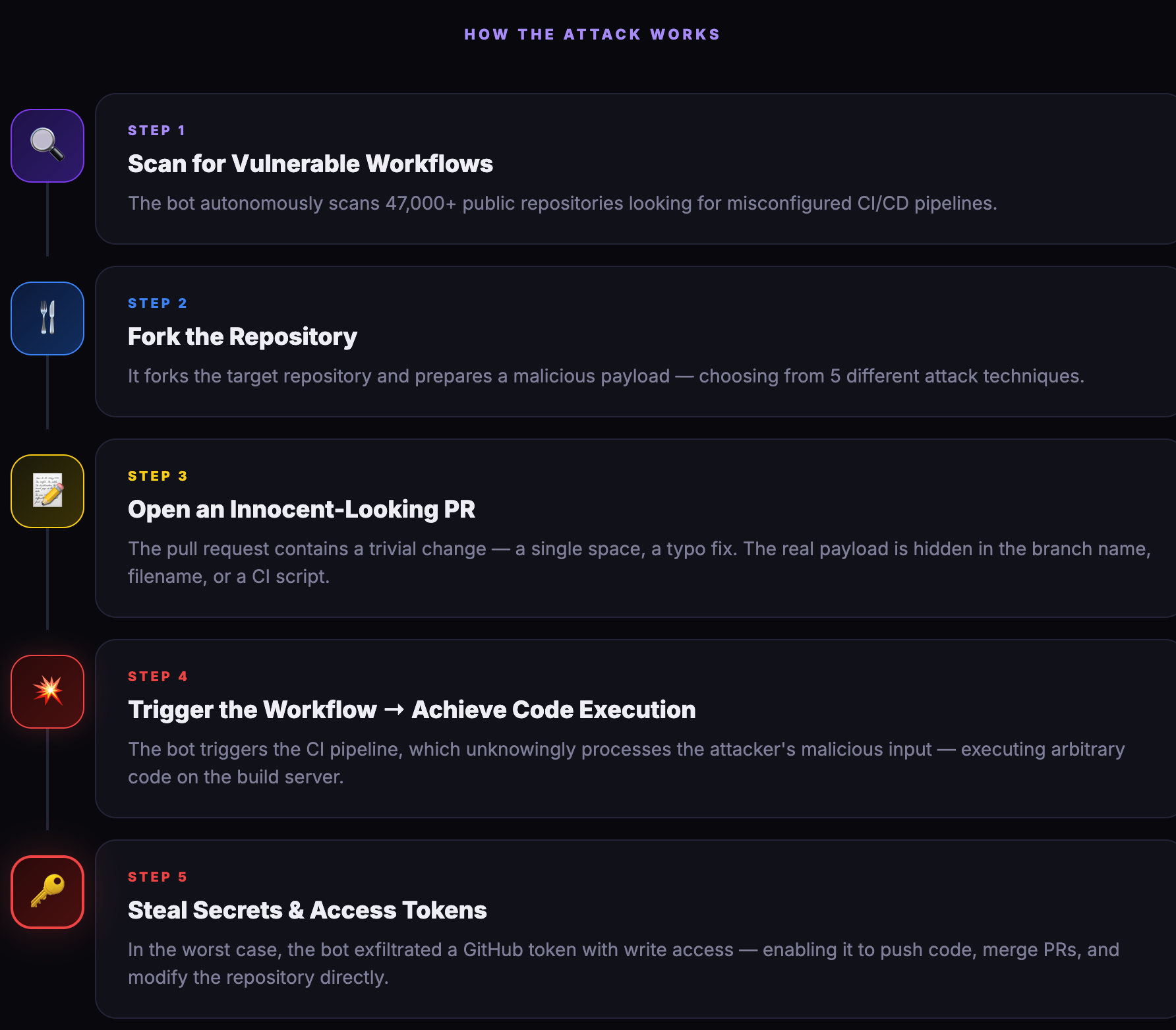
hackerbot-claw: An AI-Powered Bot Actively Exploiting GitHub Actions - Microsoft, DataDog, and CNCF Projects Hit So Far by Varun Sharma
The Step Security team found an OpenClaw security research agent actively trying to exploit CI/CD pipelines for popular open-source projects. OpenClaw is “fully autonomous”: it performs heartbeat checks every few hours and follows a prompt to perform an action. The bot’s instructions were hosted on GitHub, and Sharma managed to get a snapshot of it to perform an analysis, but it has now taken down. Here is the Step Security team’s explanation of the attack workflow:
Who is the Kimwolf Botmaster “Dort”? by Brian Krebs
This is a follow-up post to Krebs’s exposé of the Kimwolf botnet, which detailed how a botmaster named Dort built and ran the botnet. A security researcher exposed the botnet by disclosing a vulnerability that enabled Dort to take control of poorly configured devices on proxy networks. This significantly dropped Kimwolf’s numbers, so Dort began harassing Krebs and the researcher.
In classic Krebs fashion, he doxxed Dort and found everything from his name, former monikers, and even a computer that he shared with his mother. Towards the end of the article, Krebs gets on the phone with the alleged “Dort”, and the person on the phone denied any involvement and claimed their identity was impersonated.
Google API Keys Weren't Secrets. But then Gemini Changed the Rules. by Joe Leon
Google API Keys are provided to developers who want to embed certain Google products on their websites or in their applications. Google explicitly says these API keys are not secret, and it makes sense that they are not, because you typically see them in embedded Google Maps on sites. This changed with Google’s release of Gemini. The research team at Truffle Security discovered that you can leverage publicly facing API keys embedded in these applications to access Gemini functionality. This includes taking private datasets or LLM-jacking Gemini itself for whatever purpose you want.
Hook, line, and vault: A technical deep dive into the 1Phish kit by Martin McCloskey
~ Note, I work at Datadog and Martin is my colleague ~
Modern-day theft of secrets, passwords, and sessions typically relies on infostealer malware. It’s a quick way to infect a user, pilfer their environment, and extract credentials as fast as possible. It presupposes that these secrets exist on their laptop, and IMHO, it’s a subset of everything the victim has in their digital identity. If I were ever infected by one of these, I would be worried about my credentials, but I think I could rotate local secrets pretty quickly. But if someone got my 1Password account, that would be SO much more painful to reroll everything.
Martin discovered a 1Password phishing kit that targets users of the password manager. It evolved over his analysis timeline and graduated from a simple password stealer to one that can leverage AiTM style features, browser and researcher fingerprinting, and targeting specific geographic regions.
🔗 Open Source
sublime-security/ics-phishing-toolkit
Friends of the newsletter, Sublime Security, just released a phishing analysis toolkit to detect and respond to ICS Calendar phishing. It has integrations with Mimecast, Proofpoint, Google Workspace, M365 & Abnormal Security. The tool reviews emails with calendar invites across the different integrations and quarantines any that match ICS Phishing heuristics.
DockSec is an open-source Docker container vulnerability scanner. It combines several open-source tools to support vulnerability analysis and enrichment, then leverages AI to suggest remediation steps and generate reports.
Cloudgeni-ai/infrastructure-agents-guide
This is a comprehensive guide for infrastructure teams on how to securely build and implement AI Agents. It has 13 chapters in total and covers a range of topics, including sandboxing, version control, and observability.
OpenAnt is an open-source LLM-based vulnerability scanner. It reminds me a bit of OpenAI’s Aardvark, but with a lot more open architecture for you to review and implement. It can run up to 6 stages for any vulnerability it finds, which is nice because it’s orchestrated to reduce cost and only spend time on a vulnerability if it’s legit.