

DEW #139 - Detection Surface, Frontier Models are good at SecOps & THREE YEAR ANNIVERSARY!
I graduated from the terrible twos to a threenager

Welcome to Issue #139 of Detection Engineering Weekly!
It’s crazy to think that it’s been three years of doing this newsletter.
Thank you all for making this a fantastic ride. Since I like stats and insights, here are some I pulled:
15,000 subscribers as of Monday :)
138 issues in total, so not perfect, 156 straight issues, 20 weeks of downtime sounds nice to me
Two kids, one major interstate move, one grad degree and no new tattoos, though I should commemorate this somehow and get a new one :)
At least one subscriber in all 50 states in the US. California, Texas, NY, Virginia and Florida are the top 5 most-subbed states
Subscribers from 153 countries across every continent. Substack doesn’t track Antarctica :(. US, India, UK, Canada & Australia are the top 5 most-subbed countries
If you like reading Ross Haleliuk, there’s a 30% chance you are also reading me. We have the top audience overlap! Eric Capuano, Jake Creps, Chris Hughes and Francis Odum are also fantastic newsletters with high overlap
I started sponsored ad placements in September and have been booked every week since then, and 2026 is looking even crazier
This Week’s Sponsor: root
Why Detection Teams Need Minute-Level Remediation
When CVE-2025-65018 dropped last week (libpng heap buffer overflow, CVSS 7.1-9.8), the exposure window started ticking. Attackers armed with AI can weaponize CVEs within hours. Traditional remediation workflows take 2-4 weeks: triage meetings, engineering scramble, testing delays.
But here’s what detection engineers need to know: the exposure window is where attackers win. The Root team patched the critical CVE in 42 minutes across three Debian releases (Bullseye, Bookworm, Trixie), creating a fundamentally different detection posture than the same CVE unpatched for weeks. Detection strategies must account for minute-level remediation capabilities.
Learn what CVE-2025-65018 teaches us about matching attackers at AI speed and why week-level remediation cycles leave detection teams with massive blind spots.
💎 Detection Engineering Gem 💎
Turning Visibility Into Defense: Connecting the Attack Surface to the Detection Surface by Jon Schipp
I’ve been shilling the term “Attack Surface” with the detection team here at work. I think it’s a reasonable mental model to use when you need to focus detection efforts on your inventory and telemetry sources. So, when I read this post by Schipp, I was pleased to see a similar framing of the Attack Surface problem :).
The security industry has a good idea of what an attack surface is. It even has a product category vertical dedicated to it, but the definition becomes vague when you differentiate between internal and external attack surfaces. According to Schipp, the definition should focus on the assets you need to protect, which, in general, I agree with. There is no rule without telemetry, and it’s nearly a full-time job for detection engineers to identify, track, and ship the right telemetry so we can write detections.
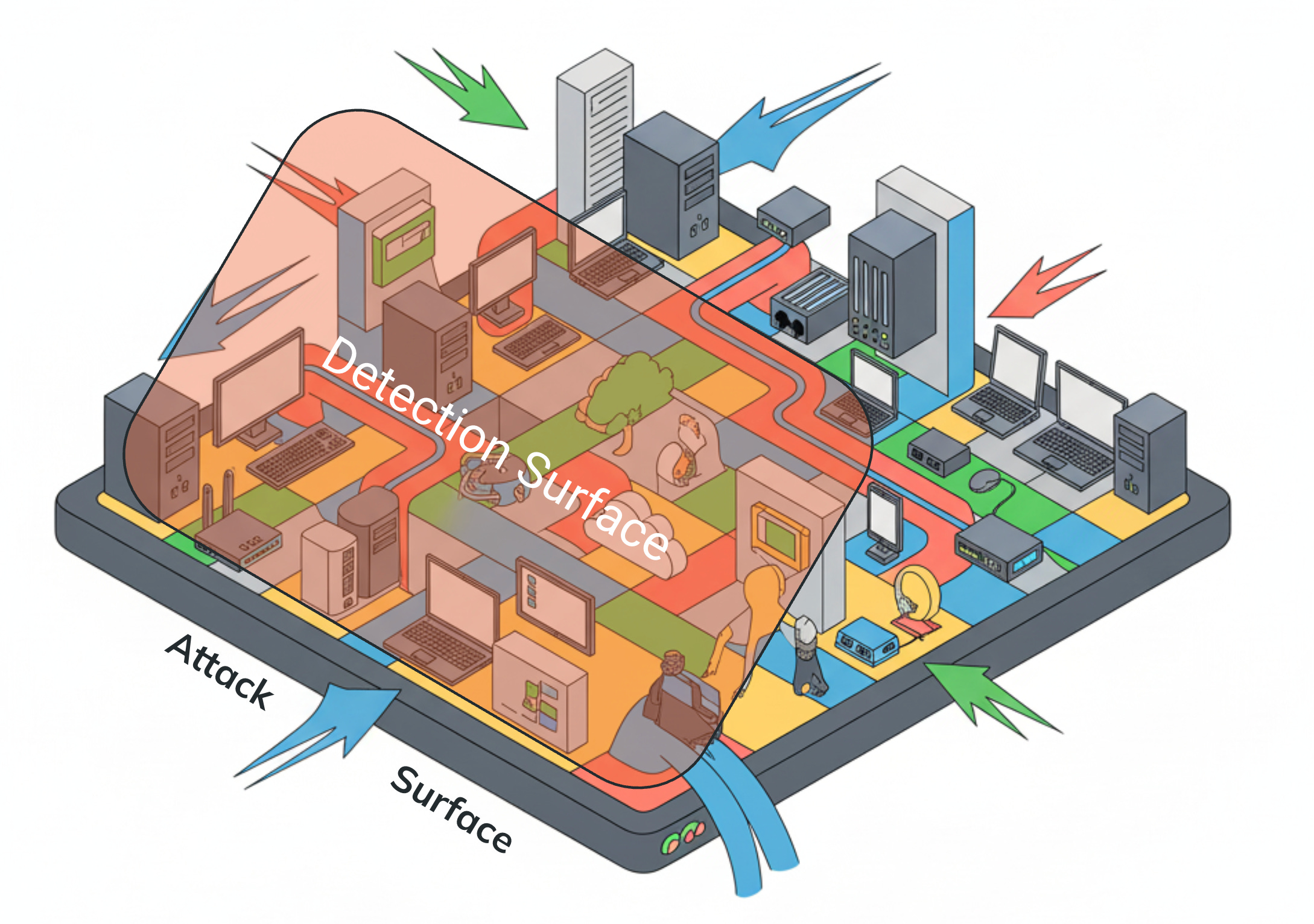
Schipp takes this a step further with the concept of “detection surface”. The adversarial behavior you want to detect can only be detected in a subset of the assets that you own. He lists a few reasons why:
Do you have the right technology selected to generate the right telemetry and alerts on top of the assets you own?
Are you prioritizing the correct detections to find adversarial behavior in the assets you find the most critical?
How do you find new gaps in coverage, and are you doing the exercise enough as your attack surface grows?
These questions are why the 100% MITRE coverage meme exists in our space. You may write rules that cover 100% of ATT&CK, but are they detecting the right behavior given your environment? I’d much rather look at a MITRE ATT&CK heatmap with deep coverage in two tactics, like Exfiltration and Lateral Movement, so I know the team is really focusing on specific behaviors to catch.
If you want to see a visceral physical reaction from me, throw a print-out of an ATT&CK heatmap that’s all green. I’ll probably run away screaming.
🔬 State of the Art
Evaluating AI Agents in Security Operations Part 1 and Part 2 by Eddie Conk
~ Note, I had Part 1 ready to go for this week’s issue and Conk & the cotool team posted Part 2. It’s important to read Part 1 so you can understand my analysis for their follow-up blog! ~
I loved reading this post because it shows how detection-as-code evolves beyond your ruleset into AI agents that handle everything from rule triage to investigations. Cotool researchers performed a benchmarking analysis of frontier models (GPT-5, Claude Sonnet & Gemini) against Splunk’s Botsv3 dataset. Botsv3 is a security dataset containing millions of logs from real-world attacks, along with a series of questions in a CTF-like format for analysts to practice investigations.
Benchmark exercises like this answer more than “are these models accurately performing security tasks?” LLMs are cost-prohibitive, as in, they require financial capital to use the frontier model APIs, and human capital to shape, maintain, and verify results. AI agent efficacy is detection and investigation efficacy. Understanding ahead of time which agents perform well within the constraints of your business can accelerate decision-making.
Here are some of the results pasted from the blog:
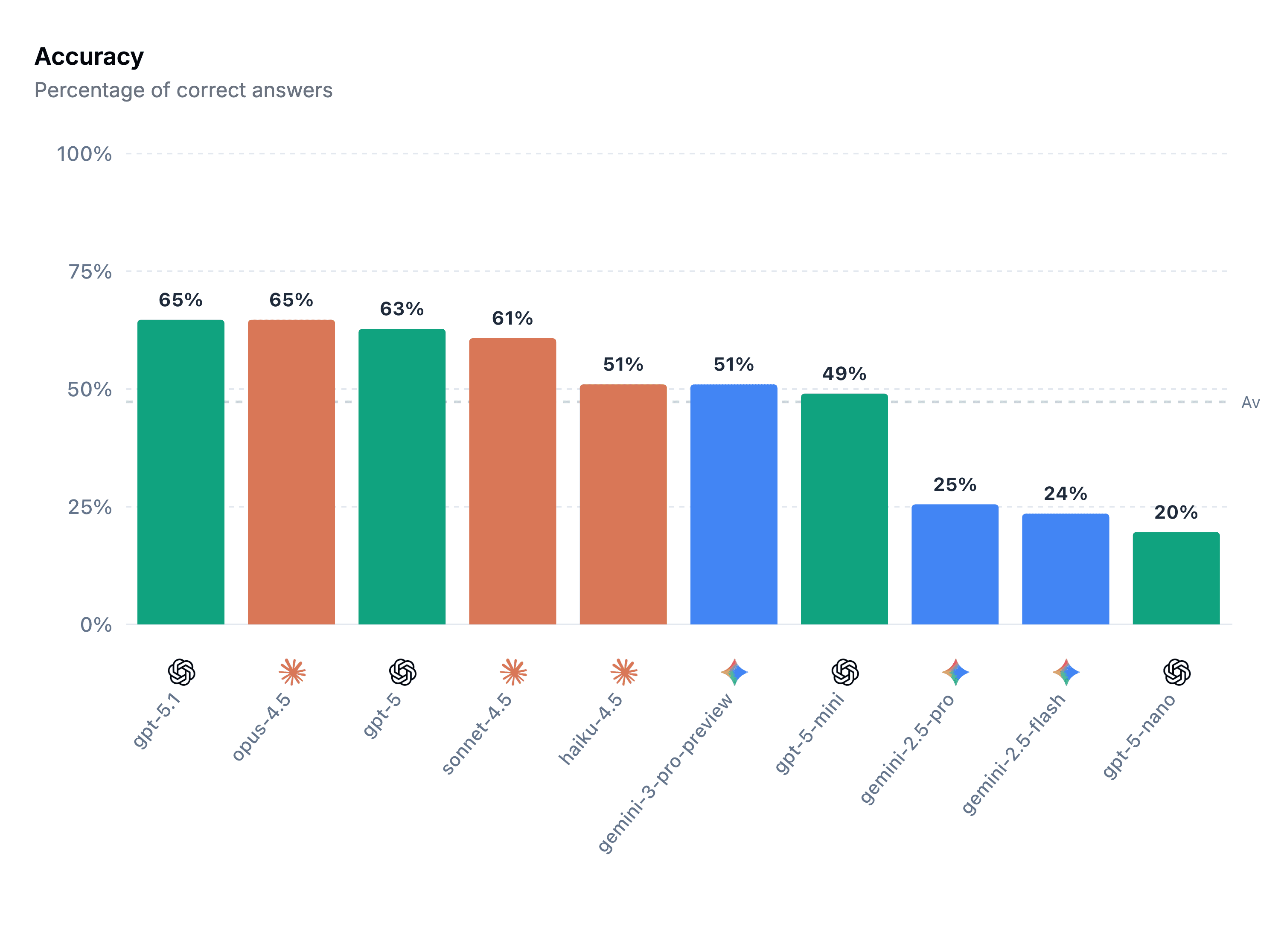
The test harness for accuracy involved taking the individual CTF questions from Botsv3 and mapping them to investigative queries. Conk and team had to remove some bias from these questions because they were built as a progressive CTF. Basically, this means that answering one CTF question unlocked the next sequential question, and that sequential question could bias the investigation.
The latest frontier models from OpenAI and Anthropic outperformed Gemini here, but I was surprised to see 65% as a leading score.
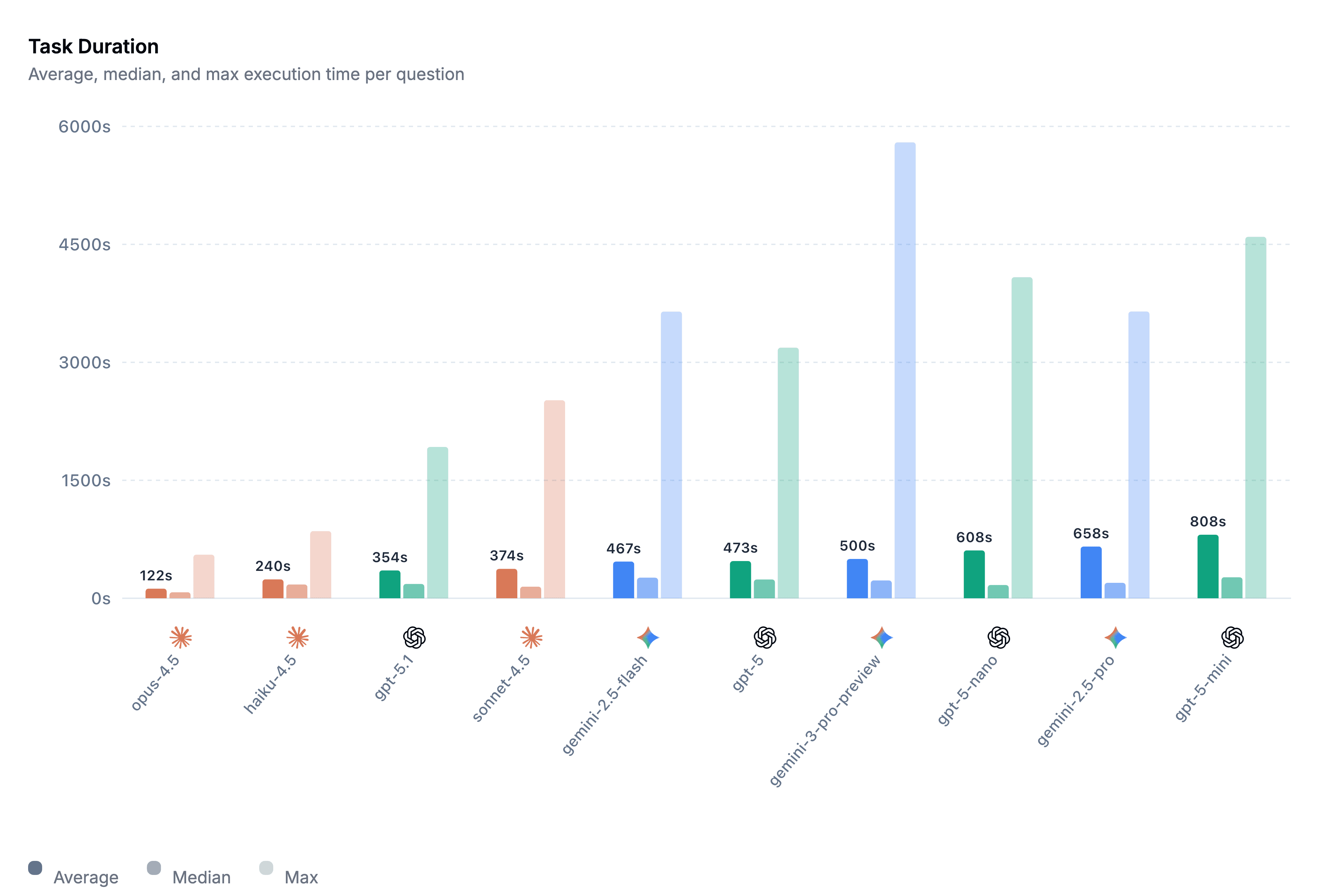
Model investigative speed now enters the equation, and Anthropic’s Opus-4.5 beat the brakes off of every other model, including Haiku and Sonnet. This is good for teams who want to tune something to be fast and accurate, which seems like a good tradeoff, and it’s off to the races, right? Well, remember, detection efficacy means cost as much as it means accuracy, and the frontrunner, Opus-4.5, costs a little over $5 per investigation versus GPT-5.1’s $1.67.
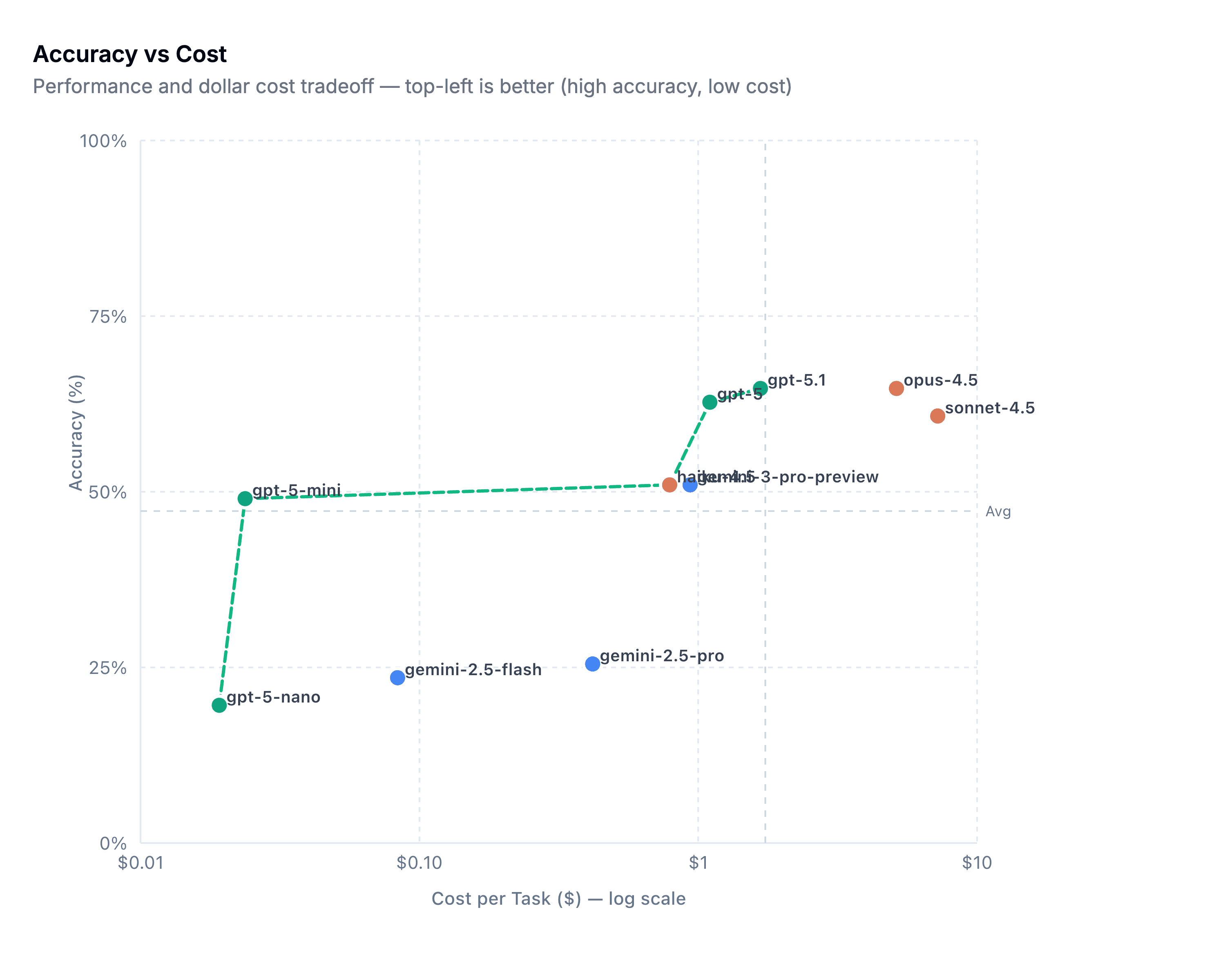
There are a few other interesting callouts in the blog around token usage, but these three axes were the most relevant for people who need to balance accuracy, speed, and cost.
The detection community needs data like this to make cost-efficacy tradeoffs for their teams. Hopefully, we can see more studies comparing models, cost, and prompt strategies, and even better, releasing bootstrapping mechanisms to run these tests on our own.
OpenSourceMalware - Community Threat Database
This is a freely available threat intelligence database for reporting and tracking malicious open-source package malware. This is especially relevant for emerging threats, such as the Shai-Hulud attack, and it’s crazy to see how many packages are submitted nearly every day. If you sign in, you can view additional analysis details of the malware submitted by researchers.
Unfortunately, there are no direct IOCs on the page, so it’s hard to pivot to hashes if you want to download them from platforms like VirusTotal. It does link to sources like osv.dev , which sometimes contain hashes, but it’d be nice to see this platform host malware samples for download.
Revisiting the Idea of the “False Positive” by Joe Slowik
This oldie-but-goodie blog by Joe Slowik on the concept of false positives in security operations really drives home the underlying issues of the label. He first frames the idea of labels like true and false positives in terms of their origins in statistics. I wrote about these labels previously, and I tried to help readers understand that their value is directly proportional to the capacity of your security operations team.
Slowik goes in the other direction in terms of their value; instead of thinking about units of work, you should think about these labels in terms of the underlying behavior and hypothesis. Analysts talk about “true benigns” in this way. You alerted on the specific behavior you wanted to alert on, but you want to investigate further to determine whether it is malicious. This breaks the pure 1-shot application of a confusion matrix and adds more work for security analysts, since we need to question our underlying assumptions about a specific detection.
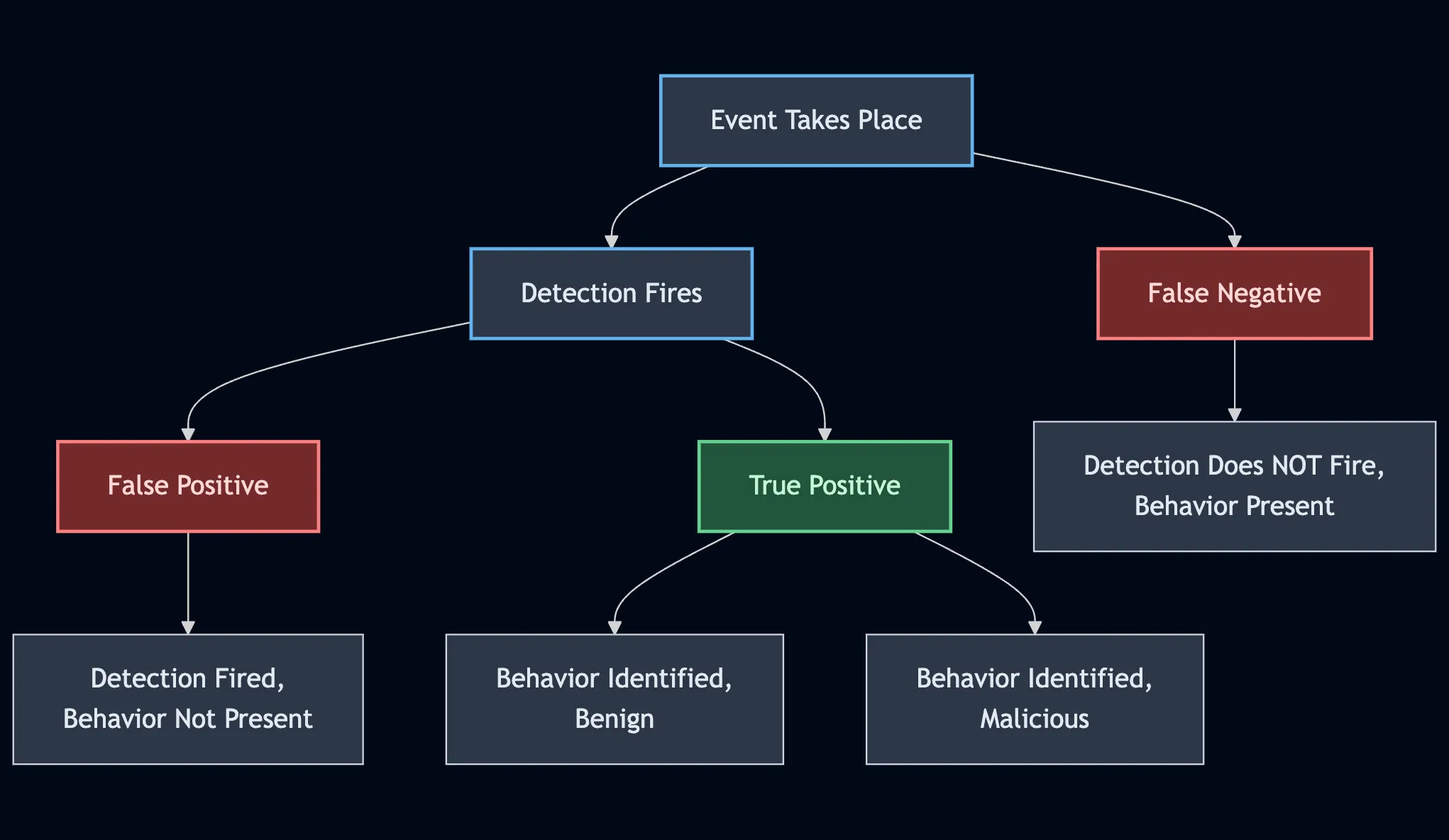
Challenging the hypothesis behind your detections aligns well with my discussion of security operations capacity versus efficacy. Here are a few questions I would ask you during this exercise:
Are you finding the right behaviors that could indicate maliciousness?
Are you okay with these behaviors generating true benign alerts, because the idea of a false negative with that behavior is detrimental?
Can the behavior you are looking for be enriched with environmental context, such as update cycles, peak traffic, or off-hours traffic?
The core of detection engineering is challenging assumptions. I hate the adage of “defenders have to be right every time, attackers have to be right once.” Finding a singular behavior to alert on across the attack chain gives us the advantage, so we really only need to be right once. So, as you build hypotheses and detection rules, you should balance what you want to see from a detection, even if it’s true benign behavior.
Intel to Detection Outcomes by Harrison Pomeroy
This is a nice introductory post to leveraging threat intelligence in detections.ai to generate detection outcomes. Full transparency: the platform has sponsored this newsletter, but it also has a community edition, so folks can sign up to benefit.
One of the hardest problems in cyber threat intelligence that I’ve dealt with for 15 years is proving tangible value. This is different than intangible value. The delivery of finished intelligence reports, RFIs, and investigative platform experiences can be considered intangible. You miss these things when you don’t have them, but it’s hard to measure the “why” behind the impact of a report or an RFI.
Detection engineering helps bridge this gap, specifically by enabling cyber threat intelligence teams to turn their research into tangible outcomes. This is what Pomeroy argues LLMs can do. You can feed an agent a cyber threat intelligence report, it can parse IOCs, TTPs, and log sources, and it can generate rules for you to try out and deploy to get up-to-date coverage of emerging threats.
Introducing LUMEN: Your EVTX Companion by Daniel Koifman
This is the release blogpost for Daniel Koifman’s LUMEN project, located at https://lumen.koifsec.me/. It’s a free tool for investigators and incident responders to load Windows evtx files for analysis. There are over 2,000 preloaded Sigma rules, and the entire analysis engine is run client-side. You can do several things once you load your logs in, such as running a sweep of the Sigma ruleset, building a dashboard on fired rules, building an attack timeline, and extracting IOCs. It has a feature to connect your favorite LLM platform to the tool using an API key and leveraging it for AI copilot capabilities.
☣️ Threat Landscape
Meet Rey, the Admin of ‘Scattered Lapsus$ Hunters’ by Brian Krebs
This is a classic Krebs doxing piece unveiling the identity of one of the main personas of The Com group, Scattered Lapsus$ Hunters. Rey was an administrator of one of the Com-aligned ransomware strains, ShinySp1d3r. It’s always crazy how he manages to pull the attribution thread to find these identities. An old message from Rey contained a joke screenshot of a scam email they received with a unique password. From there, he pivoted on the password to find more breach data tying Rey to a real person. Since Rey didn’t respond to him, Brian called his dad, and of course, Rey responded.
The Shai-Hulud 2.0 npm worm: analysis, and what you need to know by Christophe Tafani-Dereeper and Sebastian Obregoso
~ Note, I work at Datadog, and Christophe & Sebastian are my coworkers! ~
It’s rare to see the term worm inside a headline these days. It’s a rare label for a unique security phenomenon, and the idea still holds firm, this time targeting npm (again). The Datadog Security Research team put a lot of time and energy into their analysis of the latest Shai-Hulud wave. Some interesting notes from this campaign include using previous victims to post new victim data, a wiper component, and a clever local GitHub Actions persistence mechanism.
Inside the GitHub Infrastructure Powering North Korea’s Contagious Interview npm Attacks by Kirill Boychenko
Boychenko and the Socket Research team published their latest work on TTP updates to North Korea’s “Contagious Interview” campaign. It’s an impressive operation, given the scale they try to employ, aiming to conduct as many malicious interviews as possible. In this campaign, they tracked 100s of malicious packages, each with over 31,000 downloads. The factory-style setup of rolling new GitHub users with the malicious interview code, fake LinkedIn profiles, and rotating C2 servers is classic Contagious Interview.
Unmasking a new DPRK Front Company DredSoftLabs by Mees van Wickeren
To continue on the DPRK train, I found this post fascinating because it wasn’t about the malware associated with WageMole/Contagious Interview, but rather the techniques behind tracking infrastructure. Van Wickeren leveraged the reliable GitHub search engine to find malicious repositories linked to the campaign.
I was a little confused by their use of WageMole, only from a pure clustering nerd perspective. These look like Contagious Interview repositories, and the associated OSINT screenshots that call out some of them suggest that victims were taking malicious coding tests. WageMole, on the other hand, is a fake IT worker applying to companies.
At the end of the day it doesn’t matter too much because they all overlap, but its another demonstration of how hard it is to do attribution in this field.
🔗 Open Source
Full LUMEN web-app from Daniel Koifman’s blog in State of the Art above. You can host your own LUMEN instance without ever leaving your localhost!
Subdomain and attack surface enumeration tool that leverages local Ollama for AI analysis on top. It’ll connect to twenty different open-source scanning and directory services, like dnsdumpster, then push results into the local Ollama model. It looks intelligent enough to help with HTTP probing, CVE analysis, and sifting through Javascript code for anything leaked or vulnerable to standard web attacks.
Magnet leverages the GitHub API and specific query strings to find potential secrets posted to public repositories. You can specify strings or use ones provided by magnet. In their PoC, R3DRUN3 managed to find two repositories with leaked tokens, then responsibly reached out to them to provide remediation steps, and they responded.
SIEM-in-a-box for pfSense firewalls. It has an impressive architecture: OpenSearch backend, parsers in Logstash and uses Grafana/InfluxDB for metrics. It looks like they’ll be extended the SIEM backend to other open-source SIEMs like Wazuh in the future.
Awesome-* style list of hacking challenges for the holiday season. So far they have 8 listed, so if you wanted to spend some time this December to up your hacking and CTF knowledge you have your work cut out for you!