

DEW #138 - Sigma's Detection Quality Pipeline, Anthropic finds AI-first APT & eBPF shenanigans
vibing APTs, we really out here frfr

Welcome to Issue #138 of Detection Engineering Weekly!
✍️ Musings from the life of Zack:
I switched to the Brave browser, and I don’t think I’m ever looking back
My coworker suggested I go to a Tottenham Hotspur match while I’m in London. I’m a fan of one of the most insane fanbases in the NFL, where we jump through folding tables set aflame before games, and I feel that same energy from the Spurs YouTube shorts I’m watching during my research
I fractured my rib 5 weeks ago and I’m finally back (carefully) training. It feels good to move again!
This Week’s Sponsor: Sublime Security
Tomorrow: Intro to MQL, Threat Hunting, and Detection in Sublime
We invite Detection Engineering Weekly subscribers to join a technical webinar that will guide you through how Sublime Security detects advanced email threats. Learn how MQL (Sublime’s native detection language), threat-hunting workflows, Lists, Rules, Actions, and Automations all contribute to a flexible detection pipeline.
Additionally, discover how our Autonomous Security Analyst (ASA) accelerates investigations.
💎 Detection Engineering Gem 💎
SigmaHQ Quality Assurance Pipeline by Nasreddine Bencherchali
Many people claim to use detection-as-code, but I rarely see these pipelines discussed as transparently as those from SigmaHQ. In this post, Nasreddine provides readers with a complete overview of how Sigma’s community ruleset repository manages community contributions. Documentation is essential here: the Sigma team ensures that every community rule adheres to a specification, so they all appear the same, even down to the filename. Here’s their Linux rule specification:
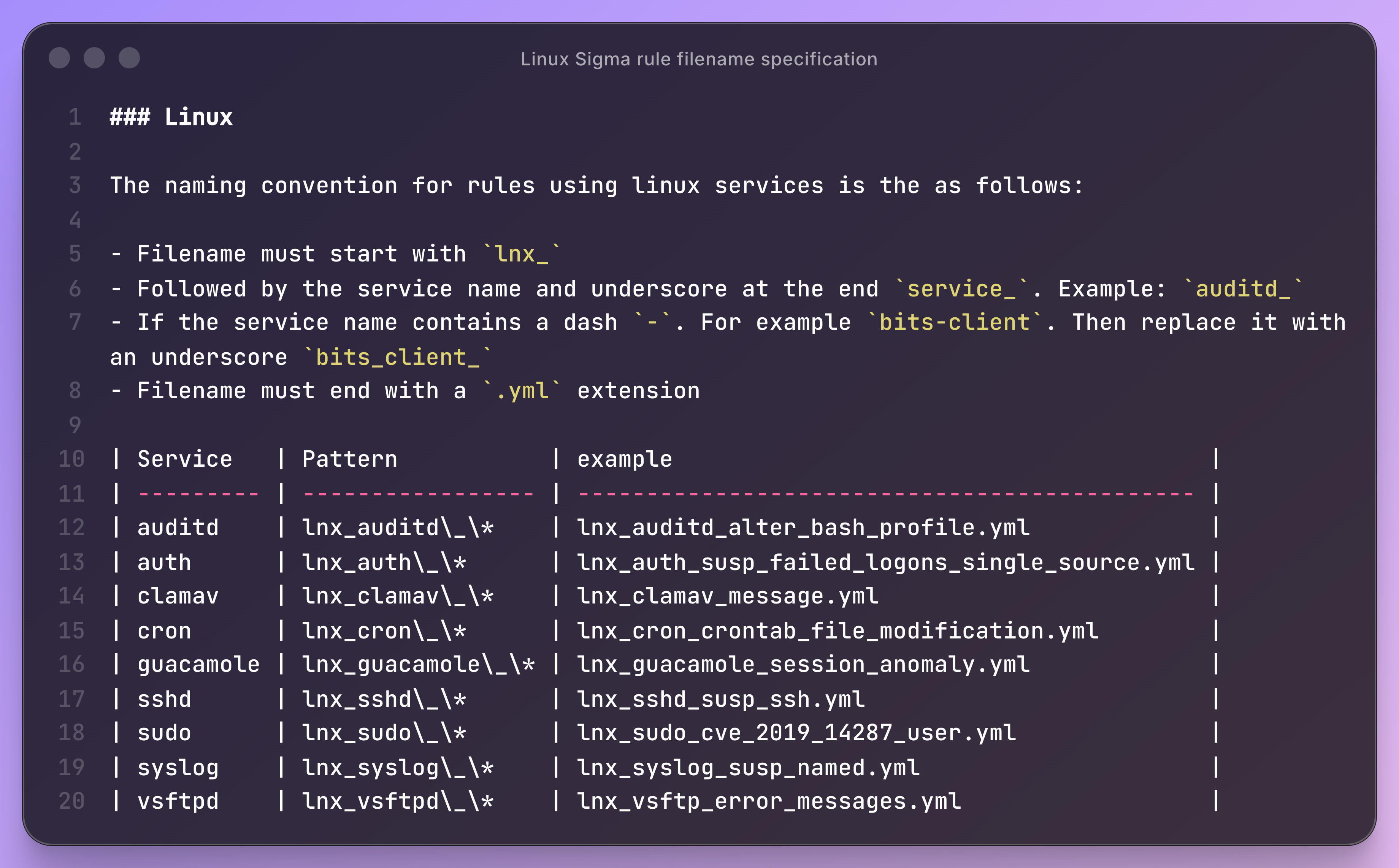
I love the attention to detail here. When you have a ruleset of thousands of rules, you need to ensure consistency in every step of the detection engineering process. It may not matter to have these conventions when you are a single team managing dozens of rules, but when you are a five-person team managing 1000s, it makes the ruleset more attractive for others to use and also keeps you sane.
The coolest part here, IMHO, is the combination of benign and malicious log validation tests. Each rule in each pull request undergoes several validators, followed by a good-log test and regression testing. The good-log test takes candidate rules and runs them across the evtx-baseline repository. If a rule generates an alert, then it must be a false positive, and the pipeline fails.
Separately, the regression testing pipeline ensures that a change in the rules doesn’t introduce any regressions that could cause false negatives and forces submitters to contribute a sample of a malicious log to validate its usefulness. The maintainers may also request reference links to blogs, threat intelligence websites such as VirusTotal, and even malware sandboxes to ensure they understand the efficacy of the rule before merging.
🔬 State of the Art
Stopping kill signals against your eBPF programs by Neil Naveen
This post is an excellent study in the cat-and-mouse game of threat detection on Linux systems. For the most part, eBPF-style security agents are the de facto standard for telemetry inspectability and detection & response. We’ve seen a lot of research in this newsletter on how effective threat actors on Windows spend time trying to disable EDRs to go unnoticed during their operations. But, I have seen few, if any, research on how to protect against eBPF attacks on Linux until I read Naveen’s research here.
When you want to terminate an eBPF agent, you’ll need Administrator privileges to do so, as they run as Linux daemons. If someone did manage to get permissions, you could send a kill signal to the process and then Bob’s your uncle. But what if you wanted to add extra steps to collect even more telemetry and find a compromise? Naveen came up with two options:
Using eBPF to hook
killand never let anything kill itLeveraging cryptographically signed nonces as an added layer of assurance to accept a
killsignal, and to keep your sanity because you just locked yourself out from restarting the agent
I’ve been doing Linux development, both offensively and defensively, for over a decade. This is probably the first time I’ve seen a clever application of cryptography to give a defense-in-depth approach to Linux detection & response. Here’s Naveen’s workflow comparing and contrasting a standard public-private key setup to a nonce-based signature kill methodology:
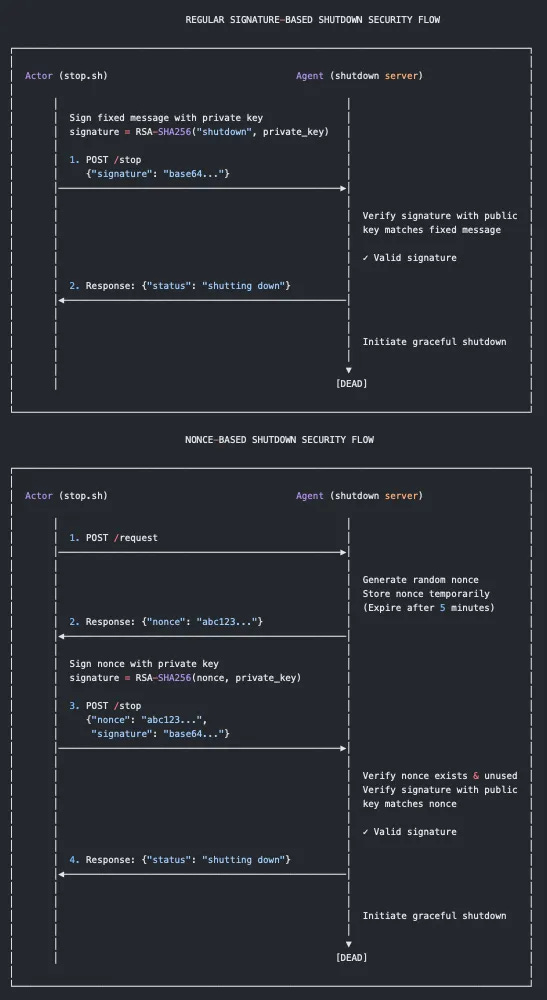
Of course, actors can also do fun stuff where they attack the Network stack directly and prevent the agent from reaching out to your security vendor’s domain for additional alerting.
Technique Research Reports: Capturing and Sharing Threat Research by Andrew VanVleet
This post serves as a follow-up to VanVleet’s research into detection data models (DDMs). DDMs are a form of documentation for detection engineers to help transcribe knowledge from an attack technique into actionable detection opportunities. But, there’s always more to a detection rule than the specific telemetry it’s trying to capture. This is where VanVleet introduces Technique Research Reports (TRRs).

The idea behind these reports is to capture the research knowledge surrounding the technique and rule. This is probably the most challenging part of our jobs, because individual research methodologies vary, and you may be an expert in a specific attack surface or style of attack, but it doesn’t do your team any favors if you can’t help them learn how you arrived to a rule. It’s even worse if you leave the team, and folks are left trying to understand the specifics of the attack, as well as the environmental context and the research you’ve performed.
I do see a lot of similarity with MITRE ATT&CK’s recent v18 launch, specifically Detection Strategies. “Identify possible telemetry” is, in general, where Detection Strategies stop and TRR reports begin. Log sources are environment-specific, and although you may have Sysmon, EDR, or syslog logs, they can become nuanced based on your environment setup. For example, a CrowdStrike vs. SentinelOne query will affect your log source query.
They are incredibly comprehensive write-ups, or “lossless” research reports, as VanVleet calls them. For example, the TRR for DCShadow attacks is a fantastic resource for detection engineers to understand the intricacies of a Rogue DC attack. It can be a blog post in its own right. However, this is where the tradeoff between documentation quality and the velocity of maintaining a ruleset comes into play.
I love this research, but given how much valuable time he invested in it, it may not be conducive to productivity unless your leadership time allows you to do so. I also worry about drift in techniques and telemetry sources, which can make some of these outdated. LLMs could help solve some of this because they are generally very good at parsing and maintaining knowledge bases.
Weird Is Wonderful by Matthew Stevens
This is a short-but-sweet commentary on the role of detection engineers and how we need to “catch the weird.” It’s always nice for me to see fresh takes on concepts I’ve talked and read about for years. When folks try to break into this industry, they are sometimes bombarded with extremely technical concepts, complex environments, and a wide array of technologies they must learn before they feel useful. But, sometimes, it’s nice to hear from others who can distill complicated subjects into easy-to-understand concepts.
Catching weird, to me, is the idea that we all succeed at our jobs when we can distinguish normal from malicious. Weird may not be malicious, so having some intuition around things that look off can help solidify the baseline of normal in your environment versus something not normal. It’s a professional paranoia, of sorts :).
Be KVM, Do Fraud by Grumpy Goose Labs / wav3
This is a follow-up post to Grumpy Goose Labs’ research on hunting for KVM switches to detect fraudulent employees. It’s full of Kim Jong-un memes, but there are excellent technical details around detecting KVM switches in your environment. The author, wav3, uses CrowdStrike as their example, and managed to dump a bunch of information on how to hunt indicators ranging from KVMs, Display settings and product indicators so you can see who among your workforce may employ some of these risky devices.
☣️ Threat Landscape
⚡ Emerging Threats Spotlight: Anthropic Disrupts First AI-Orchestrated Cyber Espionage Campaign
Disrupting the first reported AI-orchestrated cyber espionage campaign by Anthropic
Last week, the threat intelligence team at Anthropic disclosed the disruption of the “first-ever” AI-orchestrated espionage campaign by a Chinese Nexus threat actor. GTG-1002 is the designation for this threat cluster, and they attributed with high confidence to a Chinese state-sponsored operation. In this summary, I’ll break down the architecture and Anthropic’s analysis of the attack workflow, share my commentary on the parts of the report that I like and dislike, my medium-high confidence analysis of details missing from the report, and provide takeaways for detection engineers.
Attack Architecture
The most interesting aspect of this operation is that Anthropic had visibility into the orchestration layer of the threat activity, leveraging a combination of Claude and several MCP servers. They claim the threat group automated 80-90% of their operations autonomously, an impressive feat when you consider that this is a nation-state operation. GTG-1002 managed to jailbreak Claude into thinking it was talking to a red teamer, allowing them to instruct Claude to work on their behalf.
If you had told me last year that a nation-state would trust an AI system to execute its campaigns against victims, I would have (rudely) laughed in your face. But it looks pretty slick:
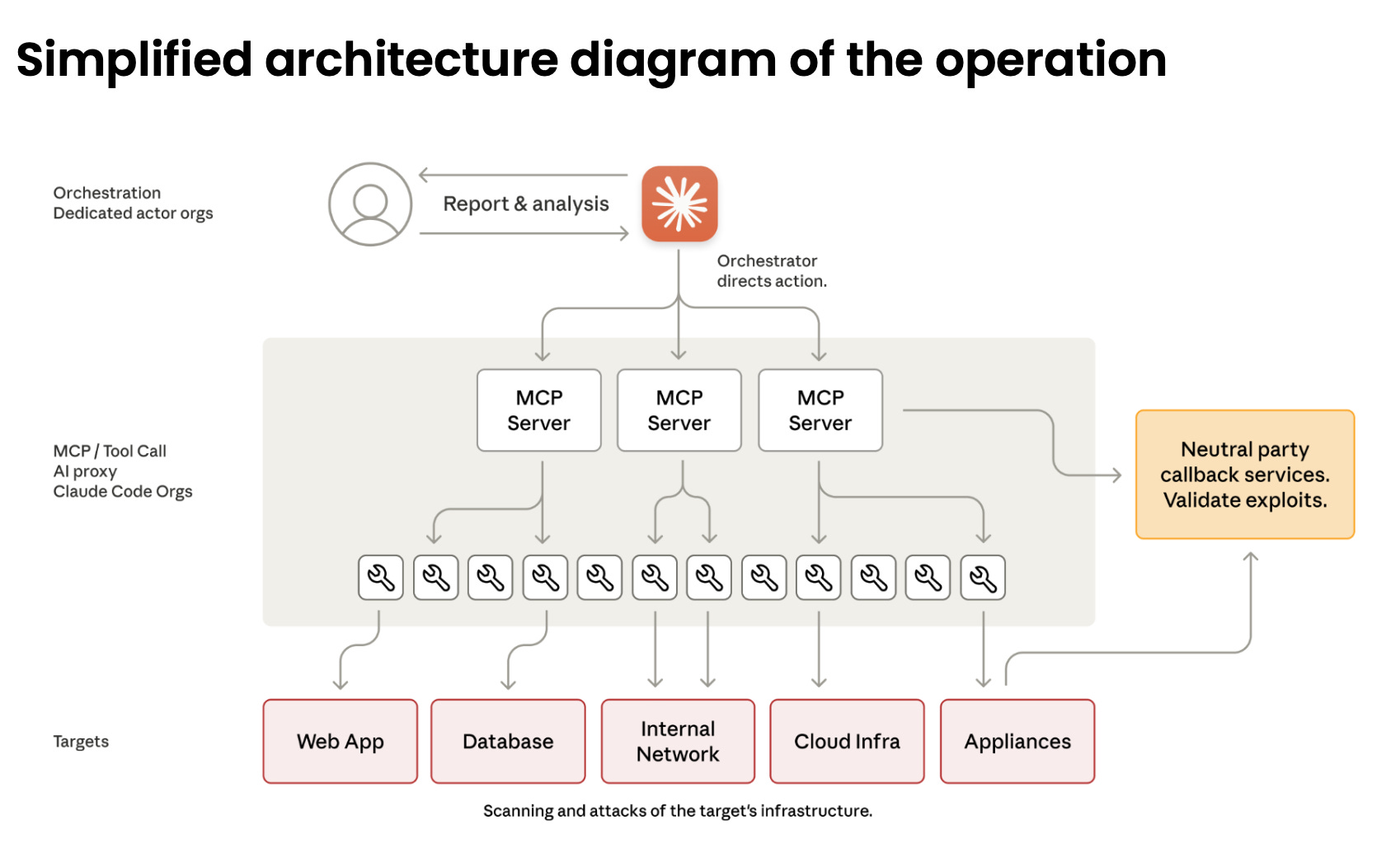
For those with a Model Context Protocol (MCP) server, it provides a standardized way to connect a human interface, such as chat or code editors, to external tools like APIs. AI applications like Claude can only use a small set of tools, so writing your own connectors to centralize your chat interface to whatever toolset you want is a powerful feature of these platforms.
According to Anthropic, GTG-1002 built a suite of MCP servers that connected to several open-source toolsets dedicated to performing reconnaissance and fingerprinting, exploitation, post-compromise lateral movement and discovery, and eventually, collection and exfiltration. This is the impressive part of the operation: imagine an operator leveraging a chat interface to create a scalable infrastructure for red team operations, with the “backend” attack tool system handled by Claude and capable of scaling as needed.
The team claims that with their visibility in Claude usage, the operators automated 80% to 90% of their attacks. The remaining 10%-20% involved human verification at the “Report & Analysis” step, as shown in the diagram above.
Attack Flow
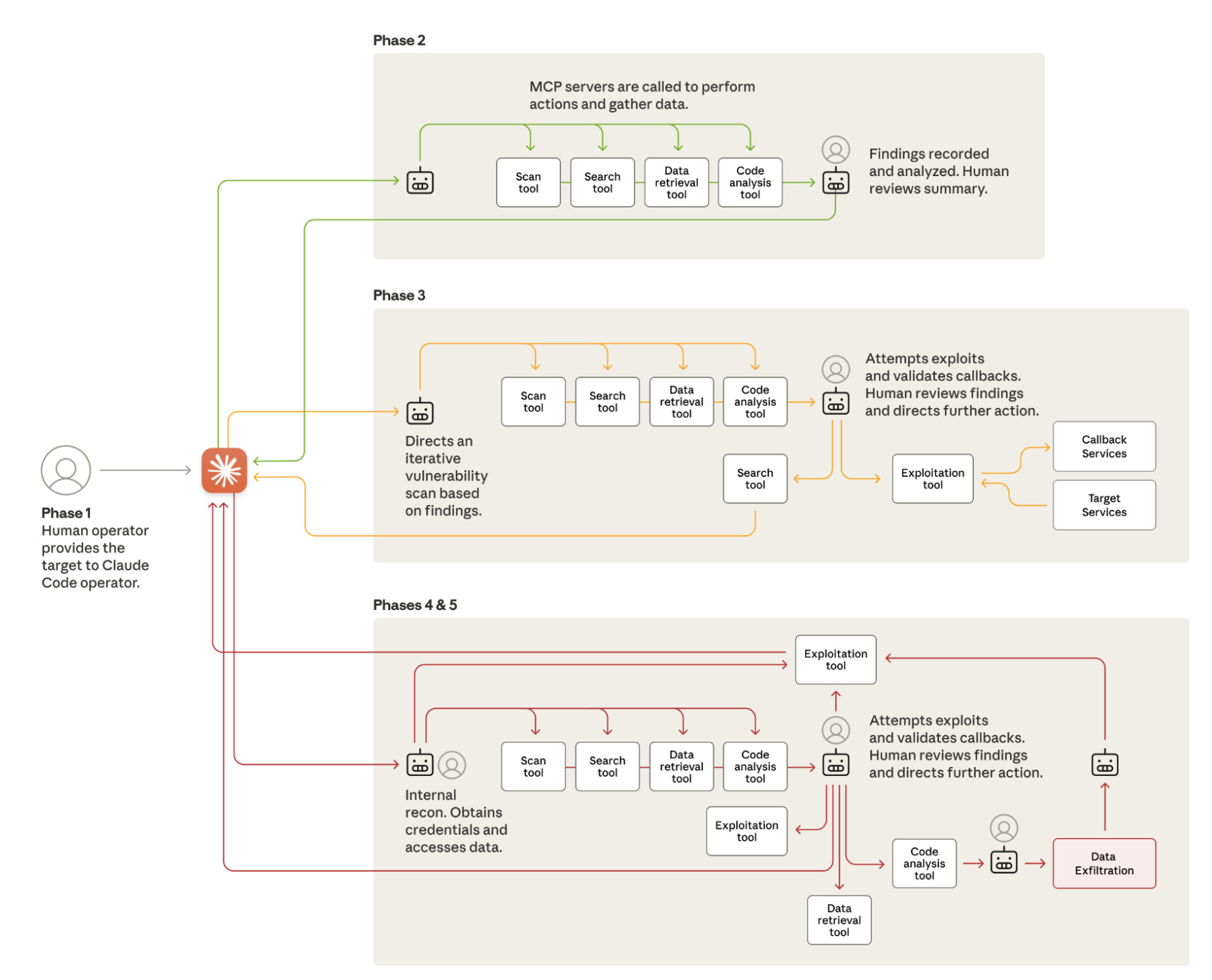
Anthropic grouped their attack operations into five phases, as shown above. The “robot” in each phase serves as the MCP server, directing specific tools to perform tasks along the ATT&CK killchain. The human icon next to the robots indicates a manual validation step by a human. These pit stops serve as a verification step to make sure that Claude is behaving correctly and not hallucinating.
In the report, the validation steps did result in a myriad of hallucinations. They claim Claude returned incorrect results, non-existent credentials, and the wrong IP addresses. So, although the attack flow diagram shows a clean, step-by-step process for the attack phase, these operations were frequently rerun.
Pros & Cons
This report has received criticism from the security community since its publication. To me, it’s a landmark report and whether it’s a famous or infamous report, it has left it mark. I want to list both what I like and don’t like about it.
What I like:
There’s an excellent demonstration of the unique visibility the Anthropic team has over attack infrastructure. It’s certainly a threat intelligence source that we can derive useful insights from, and foundational model companies like Anthropic and OpenAI can provide that
There is a specific call out around responsible disclosure to victim organizations. It shows the good intentions of the security team at Anthropic, and I hope to see more of that in the future
They admit shortcomings around how the actors performed jailbreaking to get Claude Code to help them with their operations, as well as limitations in hallucinations
The transparent technical context around the threat model of AI Trust was helpful to see and understand their day-to-day challenges
What I didn’t like:
They did not provide any indicators of compromise. No IPs, domains, hashes, signatures, or payload examples. It’s hard for research teams to verify findings independently.
The attribution is vague, and it reads like Anthropic intentionally redacted proof around this activity. Indicators of compromise could help with this
It reads as if these attacks were cloud-based instead of on-premise. I couldn’t parse out if this was differentiated, but it doesn't matter when it comes to the severity of a Chinese-nexus APT cluster. The callout about attacks against databases, internal applications, and container registries makes me think this is a cloud environment
Overall, the report provides a net benefit to security teams on several fronts. The claim of an APT using modern AI architecture from Anthropic, rather than vendor marketing, is a step forward in our understanding of an evolving threat landscape. It builds trust in Anthropic’s security team, which is one of the most used platforms for foundational models today. If we got this report from another vendor, we’d question the efficacy of their security program.
I think the feedback is valid regarding the value of threat intelligence, but I only see them improving from here.
🔗 Open Source
Technique Research Report dataset from VanVleet’s work above. It has extensive documentation of several attack techniques, and they fit the style-guide he talked about in his blog. It also includes a link to a frontend searchable library for those who don’t want to navigate the GitHub repository.
Volume Shadow Copy technique leveraging internal Windows APIs versus the command line. When you run the binary, it won’t generate any traditional Sysmon telemetry leveraging vssadmin.exe, which arguably makes it harder to detect. It has a few other tricks, including using NT API and avoids GetProcAddress usage.
Open-source and graph-based OSINT tool that looks like a more modern take on Maltego. It has dozens of transforms, so you can get a good amount of functionality out of it to compete with Maltego. The differentiation here would be hosting something on your own, and if you require specific integrations, you’d have to build them yourself.
This is a fun initial access technique leveraging the fsmonitor capability of git clients. You edit the git configuration file and set the fsmonitor value to a shell script. When git is run, the shell script executes under the hood.