

DEW #134 - Prioritizing Critical Assets, AI SOC means MORE alerts and Microsoft CoPilot Phishing
Have you tried just being 100% accurate all the time you goober?

Welcome to Issue #134 of Detection Engineering Weekly!
✍️ Musings from the life of Zack in the last week
I popped and tore muscle/cartilage in my ribs on Friday. Urgent care sent me to the ER, and the ER laughed at me and said I’m too young to hurt my ribs and come to the hospital, so they sent me home D:
I’m booking a (small) solo trip to London in December. Who’s got restaurant and more importantly Pub recommendations in the Soho area? Shoot me a message and i’ll buy you a (virtual or not) pint!
I get some AMAZING content sent to me in all kinds of mediums, but it’s hard for me to keep track. So, I made a submissions form @ https://submit.detectionengineering.net that sends your blog details straight to my Notion. If you are writing something, I want to know!
This Week’s Sponsor: detections.ai
Community Inspired. AI Enhanced. Better Detections.
detections.ai uses AI to transform threat intel into detection rules across any security platform. Join 9,000 detection engineers leveraging AI-powered detection engineering to stay ahead of attackers.
Our AI analyzes the latest CTI to create rules in SIGMA, SPL, YARA-L, KQL, and YARA and translates them into more languages. Community rules for PowerShell execution, lateral movement, service installations, and hundreds of threat scenarios.
Use invite code “DEW” to get started
💎 Detection Engineering Gem 💎
Critical Asset Analysis for Detection Engineering by Gary Katz
If everything is Priority, nothing is Priority
I think about this mantra when I am looking at team planning for our security org at $DAYJOB. Security has a thankless job in many ways: when things go wrong, we are both in the spotlight and under a microscope. When things go well, we may seem invisible to others. This means scrutiny comes at the worst times, such as during an emergency, and the amount of planning and prioritization you do beforehand can really showcase how mature you are as a security program.
Lots of detection blogs I read talk about sending telemetry into a SIEM or a logstore and how to run detection logic over that telemetry. These blogs have a large assumption: every piece of telemetry is created and maintained equally. In the real world such as business, this is the furthest from the truth. A workstation going offline versus a domain controller going offline is an example here, and what Gary calls a “chokepoint.”
These chokepoints are assets that become the biggest target for adversaries, and labeling them as Critical Assets provides clarity to your security team and your leadership team that you are putting focus in the right spots. The Critical Asset approach here requires conversations up and down your reporting chain, but it should render insights into what a detection team should prioritize first:
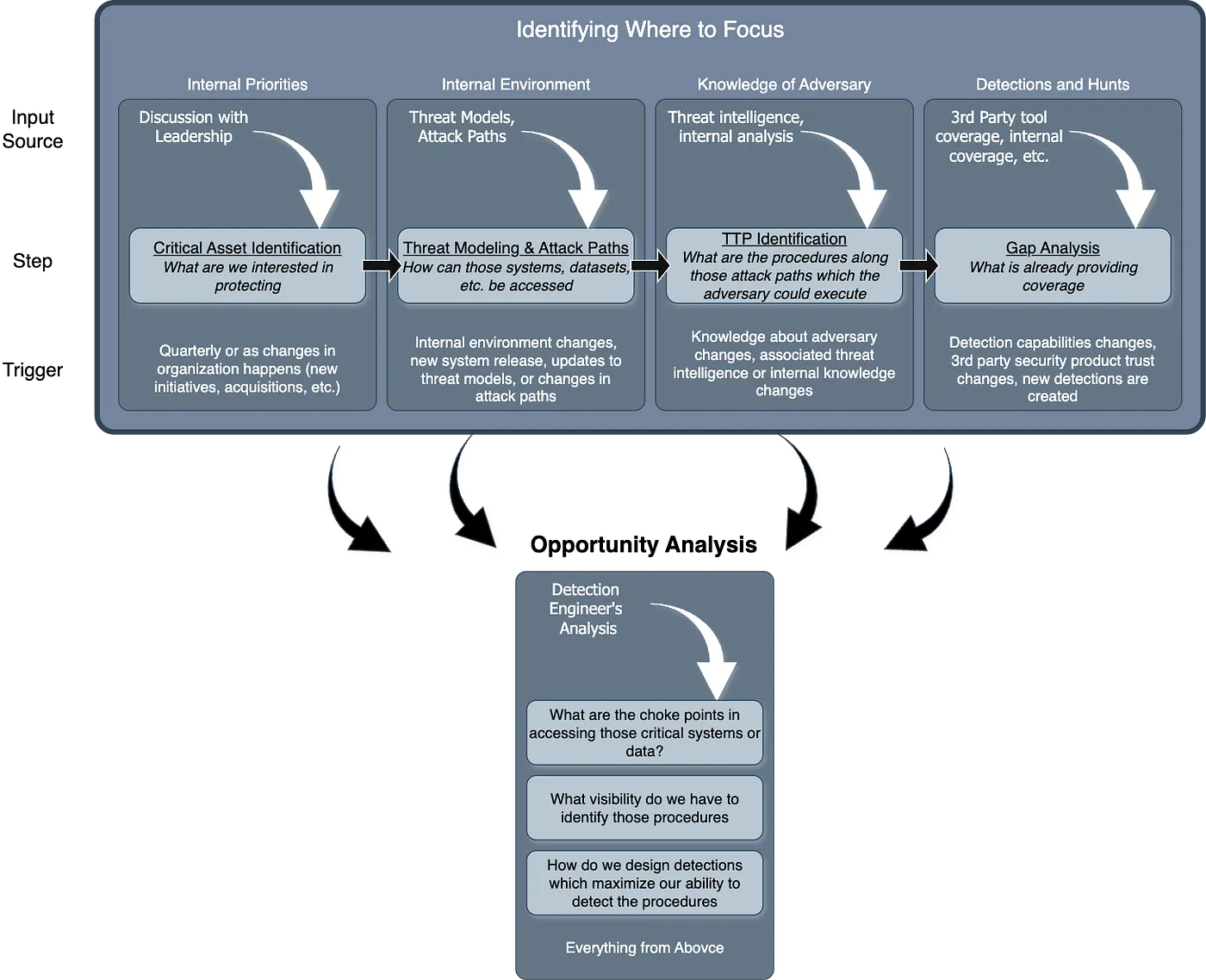
I love this approach because it shifts the conversation away from 100% MITRE coverage across everything to focused and directed coverage on your organization’s most critical services and assets. According to Katz, this methodology should output a prioritized list of assets, relevant attack paths, and coverage metrics that you can provide to others in your organization to showcase the value in peacetime (not during an incident).
The only part of this approach that I struggle with, not specifically with Katz’s but in general, is that it’s hard to highlight coverage on assets as the list grows.
🔬 State of the Art
How AI Transforms Detection Engineering by Filip Stojkovski
Like most things in security, detection engineering is a capacity problem. Every security operations function has three knobs to dial to scale their org, and they all come at some cost: people, process, and technology. SOCs address the need for scale through people, but it’s not linear because you can only triage more alerts with more people. This is where process and technology help scale the function, especially if you have a solid engineering foundation and a healthy department culture that constantly updates processes.
One of a detection engineer’s most potent “knob” is tuning how much or how little threat activity and benign traffic you capture. So, according to Stojkovski, this knob has always leaned towards precision (what we capture is relevant), as we don’t want to overwhelm the capacity of triage analysts. But, does this change with the advent of AI SOC technology?
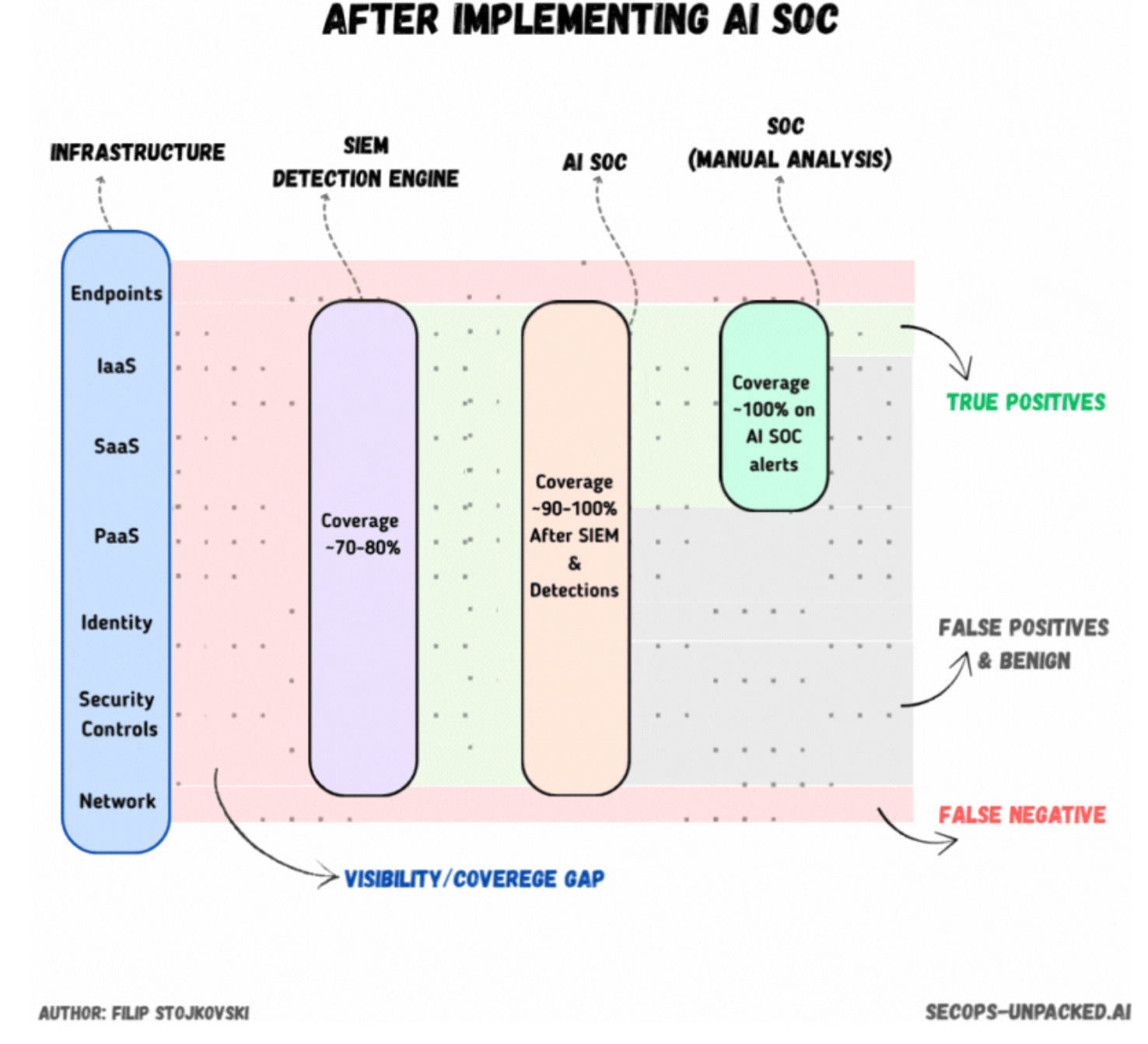
Stojkovski argues it does, and I will have to agree here. LLMs help us turn the “technology knob” way way way up, which means we gain a scale advantage that isn’t pinned to linear growth of humans. I also really like their nuance that the focus of this tech should be on true positive benigns and false positives, which means analysts focus more on real incidents versus wasting time tuning alerts that can waste 10-15 minutes of an analyst’s time.
CoPhish: Using Microsoft Copilot Studio as a wrapper for OAuth phishing by Katie Knowles
~ Note, Katie works at Datadog and is my colleague ~
AI-based features introduce risk we’ve never seen before, and it’s easy to see why the hype matters. Prompt injections lead to some funny outcomes, but the more overlooked part of AI implementation is tried-and-true vulnerabilities. Developer teams are being forced to push features out so they don’t last to market, and misconfigurations and non-standard development workflows creep into production, leaving users and organizations alike vulnerable.
This is the case with Katie’s latest research into Microsoft’s CoPilot studio. CoPilot studio is Microsoft’s workbench product for developers who want to create AI chatbots. According to Katie, it has some confusing UI/UX workflows for authenticating to a chatbot, as well as poor permission structures, which allow attackers to create OAuth Consent Phishing attacks.
.")
Desired State Configurations by smash_title
This is the first time I’ve heard of Microsoft’s infrastructure-as-code and configuration management policy language, Desired State Configurations (DSC). So, this was a helpful post for me to understand Microsoft’s approach to DevOps using native tooling from the hyperscaler. smash_title came across this technology set while creating a detection engineering-style lab for Azure Virtual Machine Windows and Linux detection testing.
It does look similar to the likes of Terraform and Ansible depending on which of the three versions you are using. There are some neat features that I don’t think I’ve seen in other similar technologies, such as drift detection and correction, and workstation resource management. It looks like Microsoft is sunsetting the earliest version that relies on PowerShell, and wants to move to a pure JSON/YAML-style declarative format, but they seem to be pretty far away from feature completeness on the newer versions.
Introducing HoneyBee: How We Automate Honeypot Deployment for Threat Research by Yaara Shriki
HoneyBee is an open-source toolset that automates the creation of honeypot stacks leveraging LLMs. Unlike other honeypots that put LLMs inside the web-app to mimic an environment, this one focuses on the configuration management and infrastructure component, which I think is a much more fruitful approach for detection engineers.
You provide access to your favorite foundational model, select a technology stack, and select one or many misconfigurations in the Wiz catalog, and it generates docker-compose files for use. This is helpful when you are building detections for specific stacks and want to see how telemetry is generated after a misconfiguration is exploited. Alternatively, you can deploy this on a honeypot listening on the Internet to collect indicators of compromise.
From Logs to Leads: A Practical Cyber Investigation of the Brutus Sherlock by Adam Goss
This is an in-depth walkthrough of the forensics challenge “Brutus” on hackthebox. I like Goss’s approach of splitting the investigation into four distinct skillsets: interpretation, collection, capability comprehension, and manipulation. Each one of these skills involves understanding a target system’s technology stack, gathering necessary data from various sources, and then using the tooling you have at your disposal to interpret the timeline of events.
☣️ Threat Landscape
[RESOLVED] Increased Error Rates and Latencies by Amazon Web Servers

What a crazy turn of events: a cascading DNS failure starting in AWS DynamoDB, which then affected an internal service supporting launching EC2 instances, which then messed up health checks on load balancers and spread through 142 separate services.
To Be (A Robot) or Not to Be: New Malware Attributed to Russia State-Sponsored COLDRIVER by Wesley Shields
This GTIG blog is a great example of how threat actors can rapidly adjust their malware development as they deploy it. Shields profiles COLDRIVER (aka Star Blizzard)’s new malware delivery chain. It uses phishing as the initial lure, which leads to a ClickFix infection. During the infection, COLDRIVER leveraged a clunky Python-based backdoor, then began simplifying the malware away from Python and focusing on PowerShell. It looks like COLDRIVER abandoned Python because it needed a Python runtime to execute, whereas PowerShell is native functionality in their victim set.
Email Bombs Exploit Lax Authentication in Zendesk by Brian Krebs
Threat actors bombarded customers of large Zendesk customers last week using flaws in how Zendesk is configured. The misconfiguration allows people who have access to company Zendesk portals to send out ticket creation notifications that come from the company domain. Most of these were spam and troll-style messages, even some accusing Krebs of breaking the law.
But it goes to show how SaaS apps have multiple layers of configuration and can lend themselves to abuse scenarios like this if someone looks hard enough.
Revelations on Group 78, the secret US task force that fights cybercriminals by Martin Untersinger and Florian Reynaud
I was skeptical reading this headline because I’ve been burned by mysterious marketing-style blog posts, but then I realized it was an expose from Le Monde. Untersinger and Reynaud provided readers some extraordinary background into the alleged FBI Ransomware Disruption Taskforce, Group 78. The goal of the group is to perform ransomware disruption operations, up to and including arrests of suspected ransomware operators. They leverage a variety of legal and more modern tactics, such as exposing criminals' identities.
The hope is to pull all the levers they can find to degrade the trust between ransomware groups, and to be honest, I like this approach. For example, Untersinger and Reynaud assert that the ExploitWhisperer leak of over 200,000 BlackBasta Telegram messages may have been from Group 78.
🔗 Open Source
smashtitle/DesiredStateConfigurations
smashtitle’s GitHub repository for their DesiredStateConfigurations research, I posted above in the State of the Art section. The cool part about this is that it’s a single PowerShell script that sets up a lab environment tailored for detection engineering on Windows. It removes a lot of B.S. out of the box services and applications that may cause a lot of noise for people who run the lab.
Repository from Shriki’s research on building honeypots using LLMs. They have a neat misconfiguration index that you can use as a dropdown in your prompt on specific technologies, so that you not only build the honeypot but also intentionally misconfigure it for detection rule coverage and lure the bad guys to exploit it.
Detonation platform for malware development and telemetry collection. The initial idea was to develop malware and test it with Windows via the DetonatorAgent Virtual Machine. It can collect telemetry from the environment as well as from EDR.
Helm Charts for various open source DFIR infrastructure built at Google. You can run things like minikube locally to take advantage of this, or even deploy it up on managed Kubernetes on AWS or GCP.
Hey, great read as always. With detections.ai using AI to generate rules, I wonder if you see that shifting the bottleneck from rule creation to the actual processing and human interpretation of the increased alerts that AI SOCs generate? You realy always have such insightful takes on these complex topics, it's genuinely fascinating to follow.