


After Issue 2, you should understand that writing, maintaining, and deploying detection rules is a core value proposition for a Detection Engineering team. These rules encapsulate human and machine knowledge in a readable form to issue queries against a security log ingestion and indexing service, typically a SIEM.
If the SIEM returns results, how do you determine whether it’s malicious activity or not?
Should a SIEM only ever return malicious results?
How do you design rules so analysts aren’t wasting time responding to the dreaded “false positive”?
This blog helps answer these questions through the lens of Detection Rule Efficacy.
Detection Engineering Interview Questions:
What are the four types of labels an alert can have — and what’s your criteria for assigning each one?
What are the tradeoffs of optimizing for TP/TN/FP/FNs?
From a Detection Rule Efficacy perspective, what makes a good rule versus a bad rule?
Security Operations is a Funnel
One of the most impactful pieces of security operations work I’ve ever read is Jared Atkinson’s research into the “Funnel of Fidelity” for alerts - link to the post here.
The basic premise of the Funnel of Fidelity is that security teams have limited capacity based on the number of humans reviewing alerts. For each new alert pushed into the analyst’s queue, some level of cost is imposed on the analyst as a function of time to investigate that alert. Therefore, as detection engineers, we must consider the fidelity of our alerts in terms of their associated costs.
Jared’s post captured this with his concept of the Funnel of Fidelity, and forewarned readers to “Never clog the Funnel”
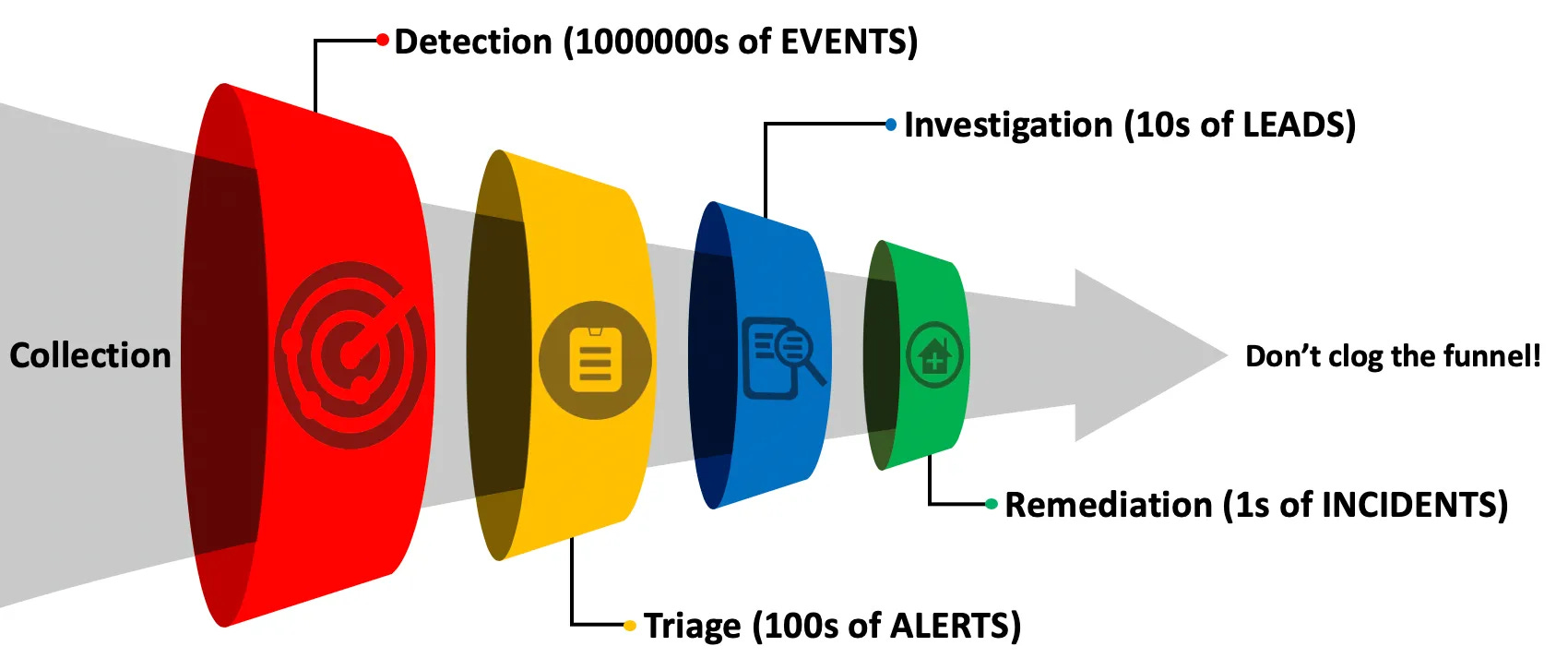
In Issue 2, while describing the function of detection rules, we explored the idea that these rules help scale human operations, so we aren’t consistently stuck issuing queries against a SIEM to look for maliciousness.

We rely on both rules to capture our human intuition and querying services to find logs that may indicate maliciousness. This is the same argument Jared discussed in his post: with limited resources (time to triage alerts and the number of humans triaging them), how can we prevent alert fatigue?
We define alert fatigue as the degradation of human efficacy in triaging alerts, which can result in malicious telemetry bypassing our human investigations, thus leading to a security incident or, worse, a security breach. The concept of the Funnel helps prevent alert fatigue by focusing detection efforts on this cost function; we can’t do that without understanding the four types of alerts that can reach the “Triage” portion of Jared’s Funnel.
Scaling Security Operations is an optimization problem
I never really understood the purpose of mathematics through my schooling and college until I realized that most problems in security aren’t solved, but optimized. A Detection Engineering team focuses on Detection Rule Efficacy, which is the cost function of generating alerts via their rules relative to the capacity they can handle without clogging the funnel.
To understand Detection Rule Efficacy, you must have a foundational understanding of the four labels in any prediction-based system: True Positives, False Positives, True Negatives and False Negatives. These labels are useful for almost any binary classification system. Don’t worry, we aren’t going deep into Statistics or Machine Learning, instead we are going to use these labels as a way to understand the risk of clogging the funnel.
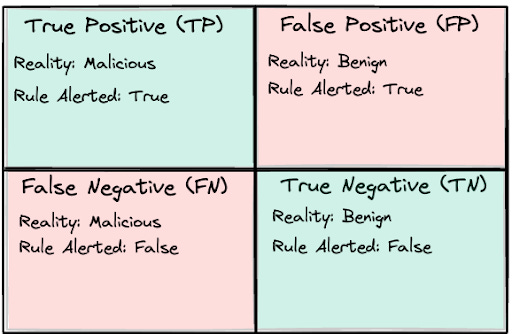
There are two realities to any alert:
What an alert is, such as the traffic or log, is whether it is malicious or benign
What we interpreted what the alert was, which is malicious or benign
So, to be explicit on the four labels:
True Positive: There was malicious traffic, and we labeled (alerted) that traffic as malicious
False Positive: There was benign traffic, and we labeled (alerted) that traffic as malicious
False Negative: There was malicious traffic, and we did not label (alerted) that traffic as malicious
True Negative: There was benign traffic, and we did not label (alerted) that traffic as malicious
In the ideal state, all of our rules alert on true positives and do not alert on true negatives. However, if you recall any of your statistics classes (I certainly didn’t, but I’ve read a lot since then), it’s never that easy. In fact, it’s probably impossible in any classification system. Let me explain.
Precision and Recall make our rules Brittle and Broad
My favorite way to describe the issues of Detection Efficacy is through Brittle and Broad rules, also coined by Jared Atkinson. Broad Rules capture a wide range of malicious telemetry, but are prone to false positives. Brittle Rules capture a particular type of malicious telemetry, but are susceptible to false negatives. In the statistics world:
Brittle Rules measure Precision, which is the ratio of TP/TP+FP
It answers the question: Of the set of alerts, how many are relevant (malicious) events?
Broad Rules measure Recall, which is the ratio of TP/TP+FN
It answers the question: Of the relevant (malicious) events, how many were alerts?
Let’s get visual with these concepts, shall we?
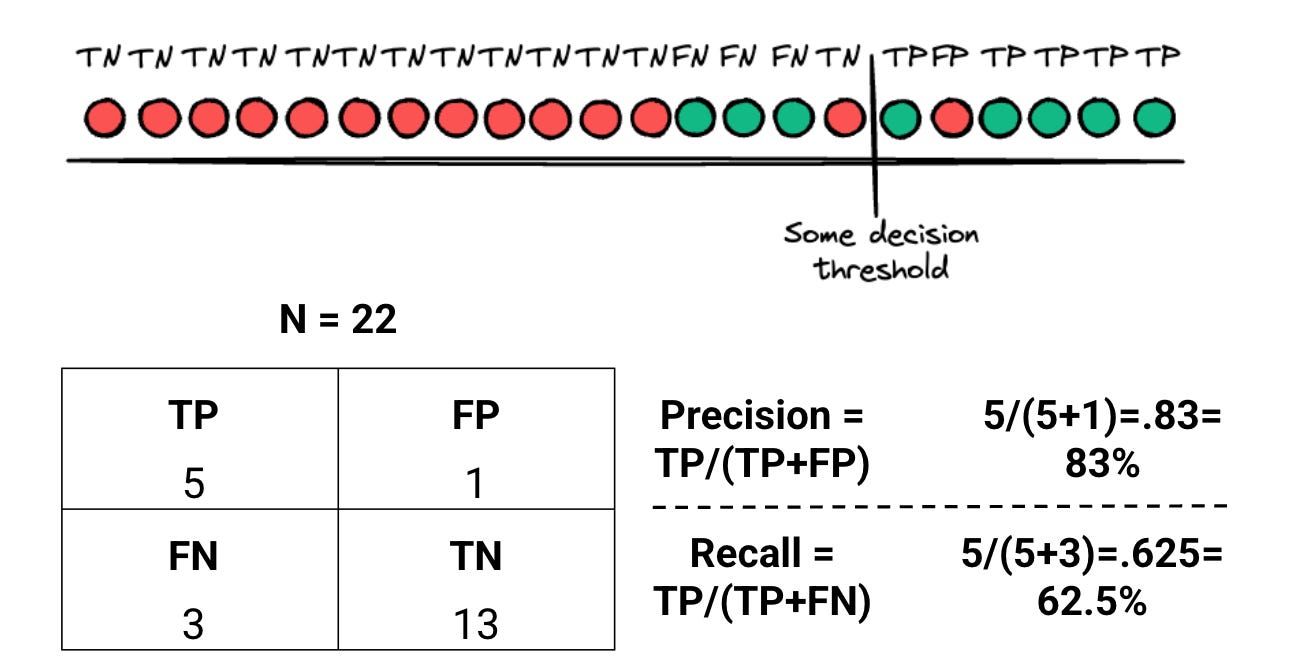
In the above visual:
There are 22 logs (N=22)
8 logs are malicious
14 logs are benign
You deploy a detection rule, and you alert (the decision threshold on the line at the top) on 5 of those malicious logs, and 1 benign log. The Precision (Brittleness) of your rule is calculated as:
5 malicious alerts / (5 malicious alerts + 1 benign alert) = 83%
83% is not bad! For every 100 logs, you alert correctly on 83 of them. But there’s a catch to this Brittleness. Let’s calculate the Recall (Broadness) of your rule:
5 malicious alerts / (5 malicious alert + 3 malicious events you missed) = 62.5%
For every 100 malicious events, your detection catches about 62 of them. Is that good or bad?
I’ll be lame and propose the “Allen’s Rule of Detection Efficacy” (I’ve always wanted to have something named after me, so give me this one, okay?)
You can’t have a detection rule that’s both perfectly precise and fully comprehensive unless you already know the answer.
This is a perfect shoe-in for Atkinson’s “Clogging the Funnel” concept. He never proposed making all of your rules high precision (brittle) or having high recall (broad). He suggested that we consider the efficacy of our rules to avoid overwhelming the SOC. It’s an optimization issue.
Detection teams combat this optimization in various ways, including threat and breach emulation, threat hunting, detection-as-code testing, detection tuning, and integrating rules into live traffic, which we’ll explore later in this series. We have numerous strategies to optimize efficacy, but what does efficacy mean in the context of a good rule?
Good Rules Provide Operational Value
A SIEM alert is a unit of work for a SOC analyst, a detection and response engineer, and a security engineer. At its minimum value, it’s a hedge to the downside cost of a security incident. You’d rather alert and contain a suspicious process that executes malicious code on a company asset than miss the attack, which could lead to a full-scale security breach. So, when you are asked what makes a “good” rule versus a “bad” rule, it comes down to how much cost are you willing to incur for responding to that alert.
To drive this point home, let’s look at a larger population of security events, this time with low precision and high recall:
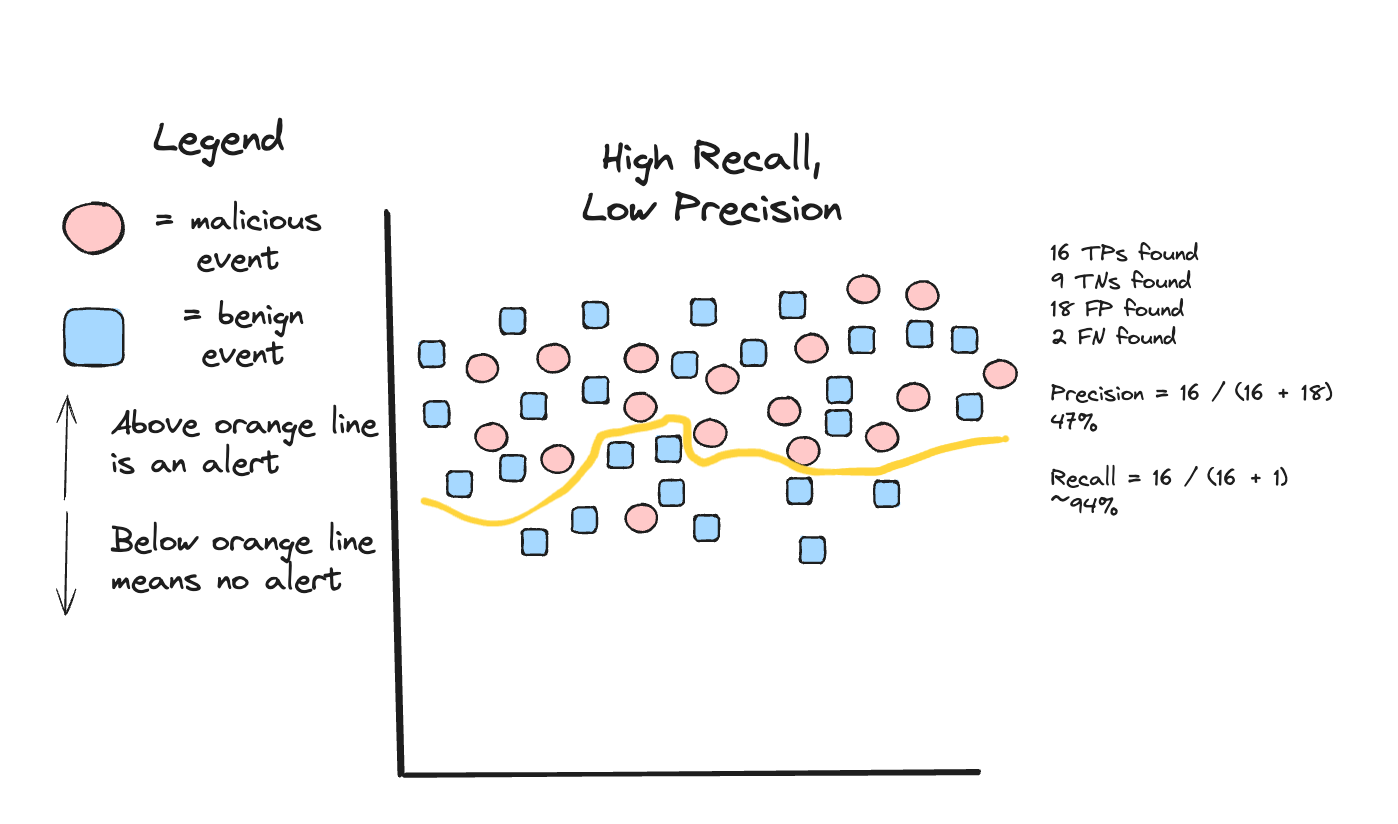
At face value, this rule might be deemed a “bad” rule. The precision here is 47%, which means that for every 100 alerts, only 47 of them are malicious. That means 53 false positive alerts incur an unnecessary cost on an analyst. The recall is very high: for every 100 malicious events, we catch 94 of them. So, is this a bad rule or not?
Here are some counterpoints to where this might be a good rule:
The SOC is concerned about missing a specific attack that this rule aims to detect, so they build in the capacity to triage more false positives to ensure they don’t miss any malicious alerts.
The rule is experimental and is being “baked” into the operational environment, so false positives are expected and welcomed to help tune the rule (move the orange line)
This is a threat hunting rule where precision doesn’t matter, and the detection engineer wants to cast a wide net to find all kinds of events.
The rule has a low criticality marking, or severity (INFO, LOW, MEDIUM, HIGH, CRITICAL). Based on SOC’s operational context, INFO/LOW/MEDIUMs aren’t triaged first, and could be used as a signal rather than an alert.
Given the four examples above, it is reasonable to conclude that this rule provides operational value and is a “good” rule. As long as you don’t clog the Funnel of Fidelity, then you should have an efficient security operation, and have more resiliency and flexibility in your set of rules than you would have if you only focused on Brittle rules.
Conclusions
Detection Efficacy is more than just tuning rules to generate true positives and avoid false positives. Efficacy provides operational value to the detection engineer and their customers, and sometimes that means generating alerts that may not be useful from a pure precision point of view.
Atkinson’s Funnel of Fidelity is an excellent way to model how you should run a security operations program. It allows flexibility in your ruleset and encourages conversations outside of the Detection Engineering bubble to understand what matters to your operational teams and the firm as a whole.
Would love to have this in a physical book😝